Grammar of data visualization
Lecture 2
2026-01-14
Tour: Quarto (and more Git + GitHub)
Option 2:
Go to RStudio and open the document ae-01-income-inequality.qmd.
Tour recap: Quarto
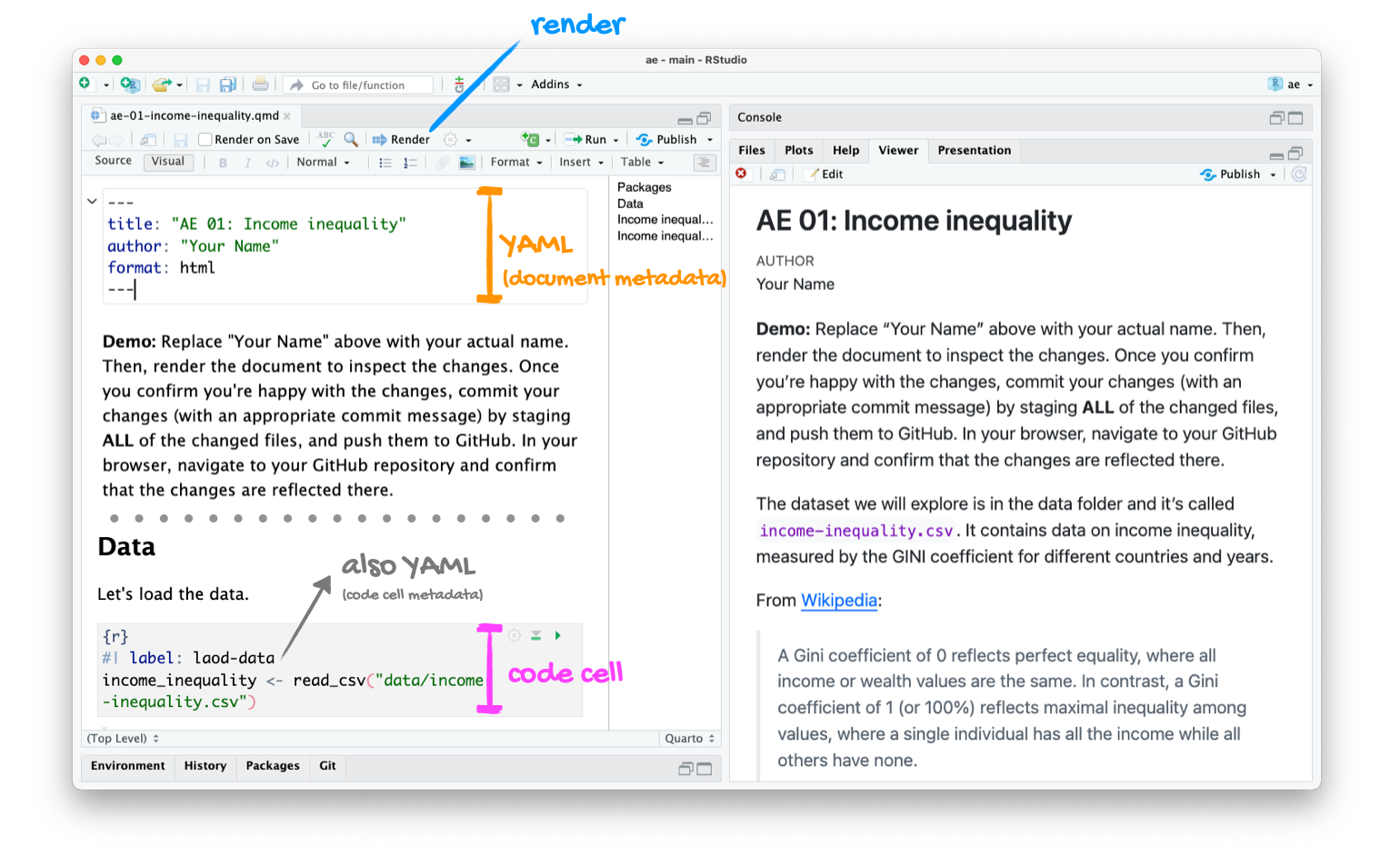
Tour recap: Git + GitHub
Once we made changes to our Quarto document, we
went to the Git pane in RStudio
staged our changes by clicking the checkboxes next to the relevant files
committed our changes with an informative commit message
pulled from GitHub to make sure we had the latest version of our repo
pushed our changes to our application exercise repos
confirmed on GitHub that we could see our changes pushed from RStudio
What does this picture communicate?
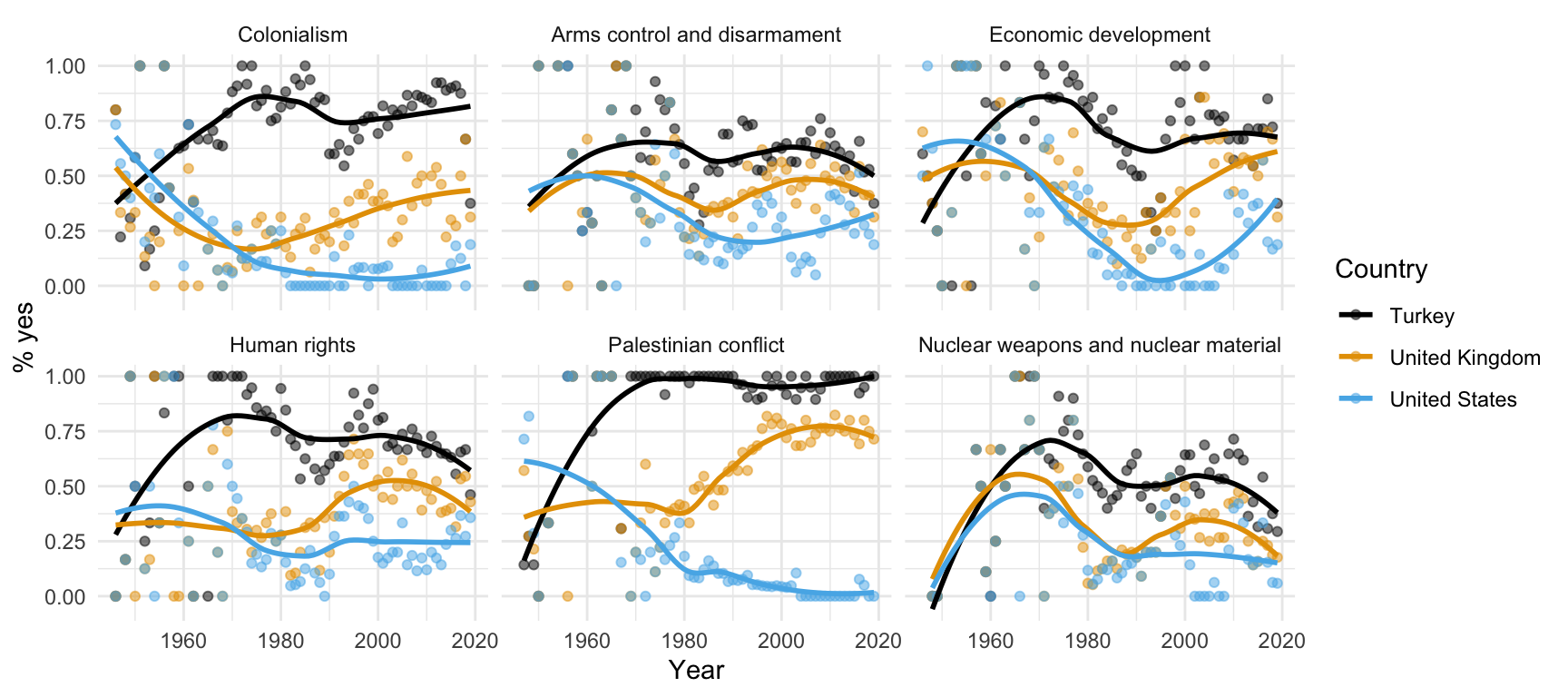
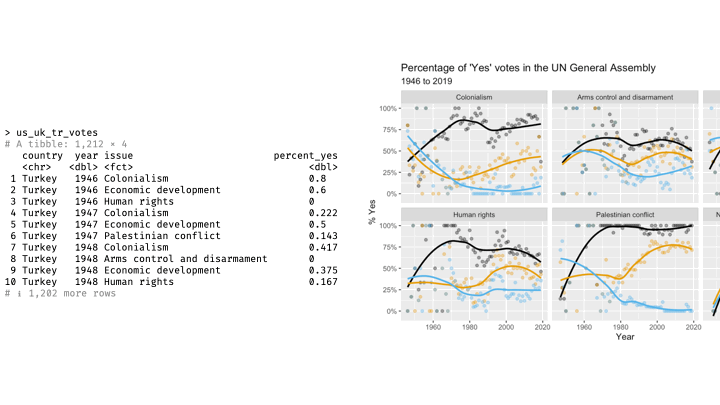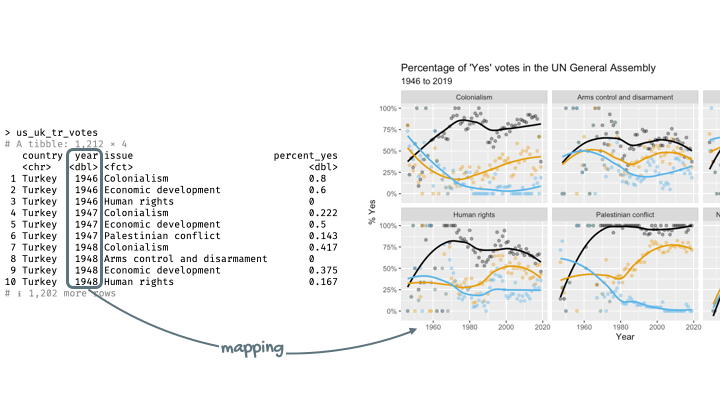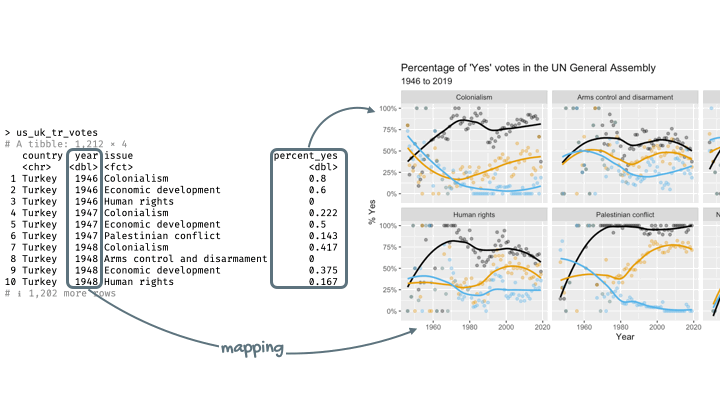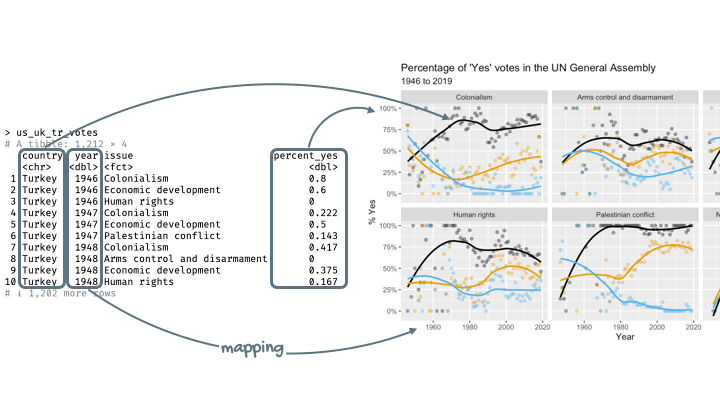
Remember this visualization from the code along video – what was it about?
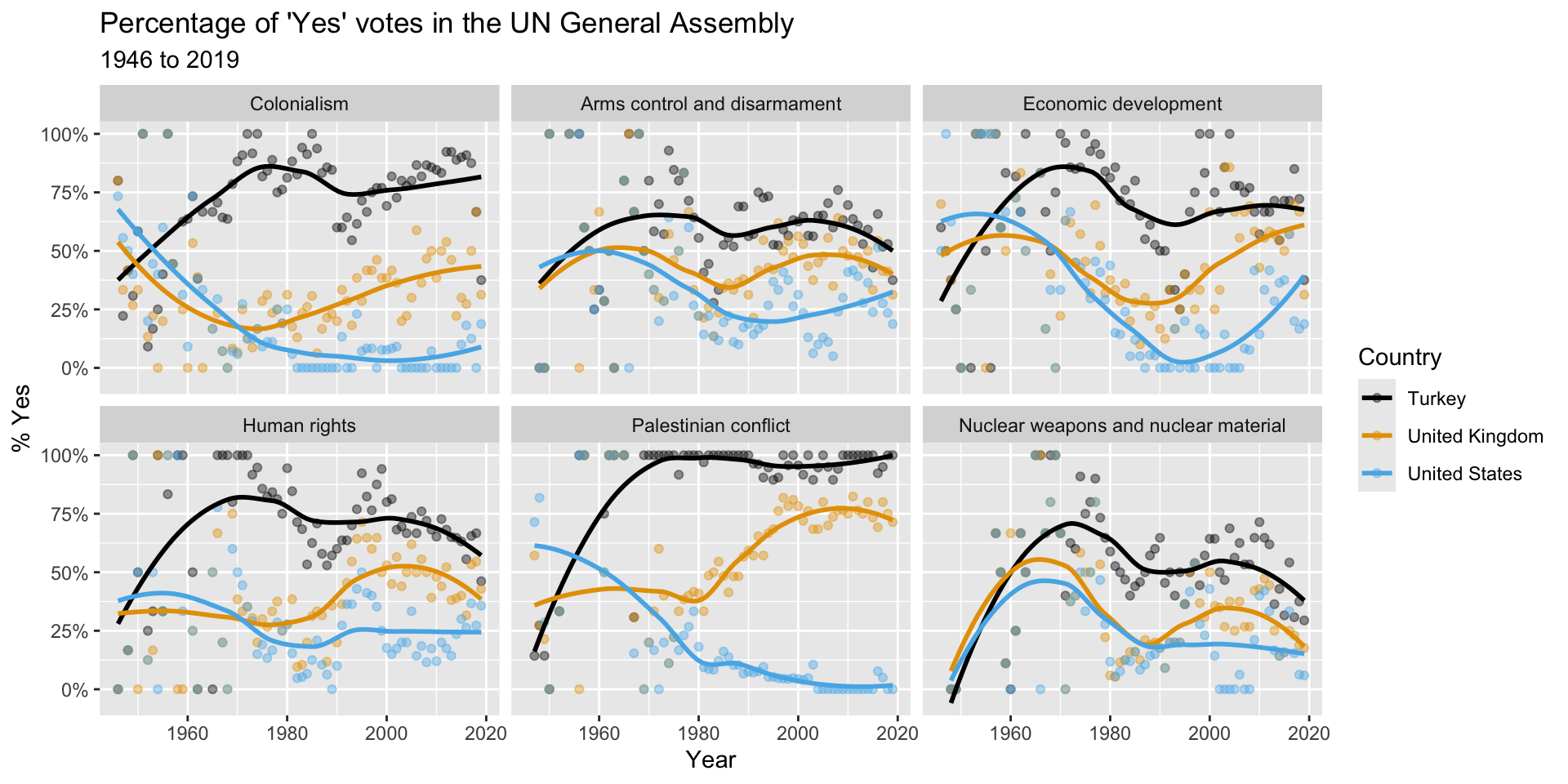
Visualize the data
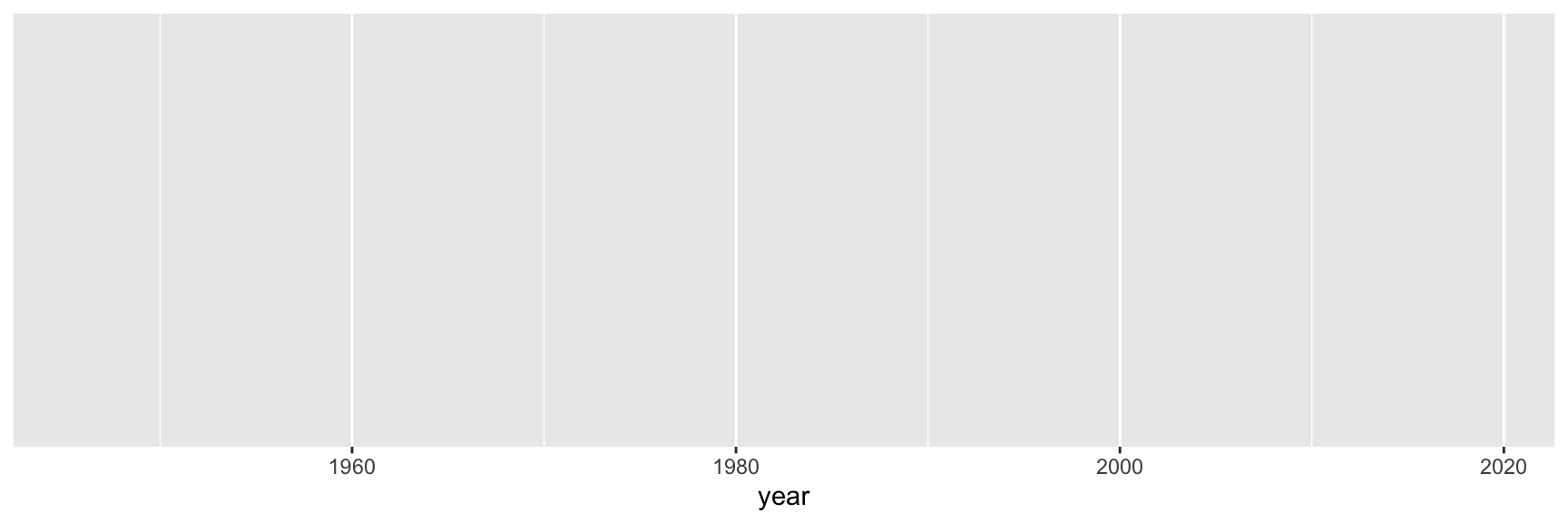
Step 1. Prepare a canvas for plotting

Step 2. Map variables to aesthetics
Map year to the x aesthetic
Step 3. Map variables to aesthetics
Map percent_yes to the y aesthetic
Mapping and aesthetics
Aesthetics are visual properties of a plot
In the grammar of graphics, variables from the data frame are mapped to aesthetics
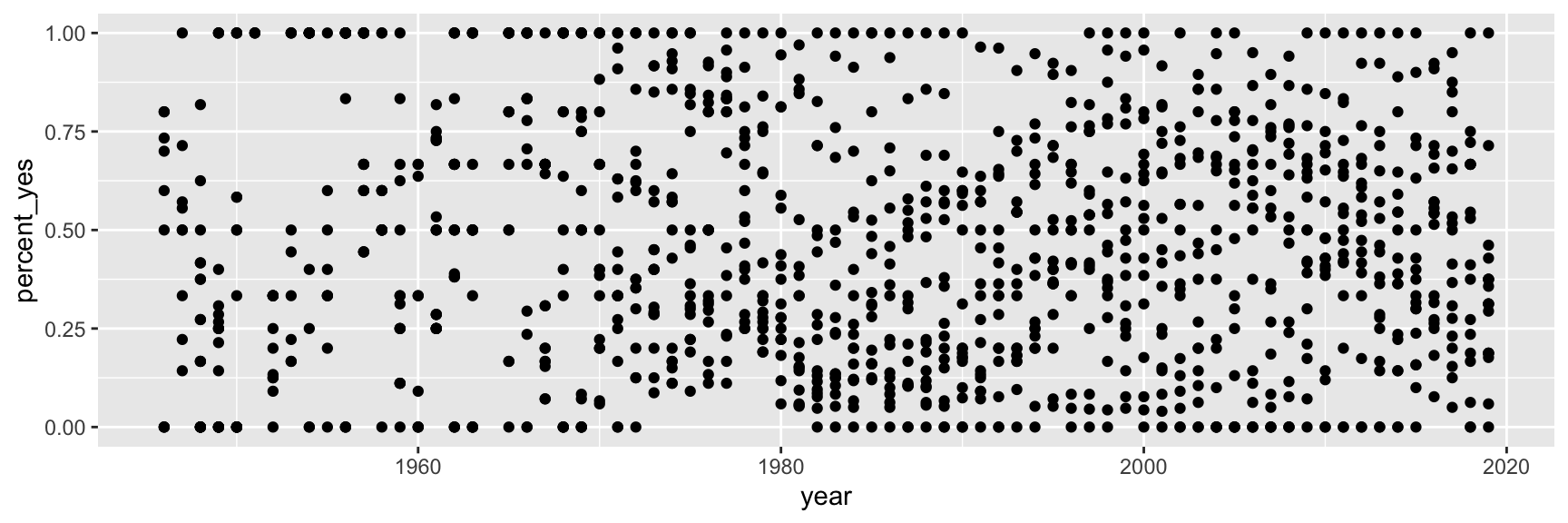
Step 4. Represent data on your canvas
with a geom
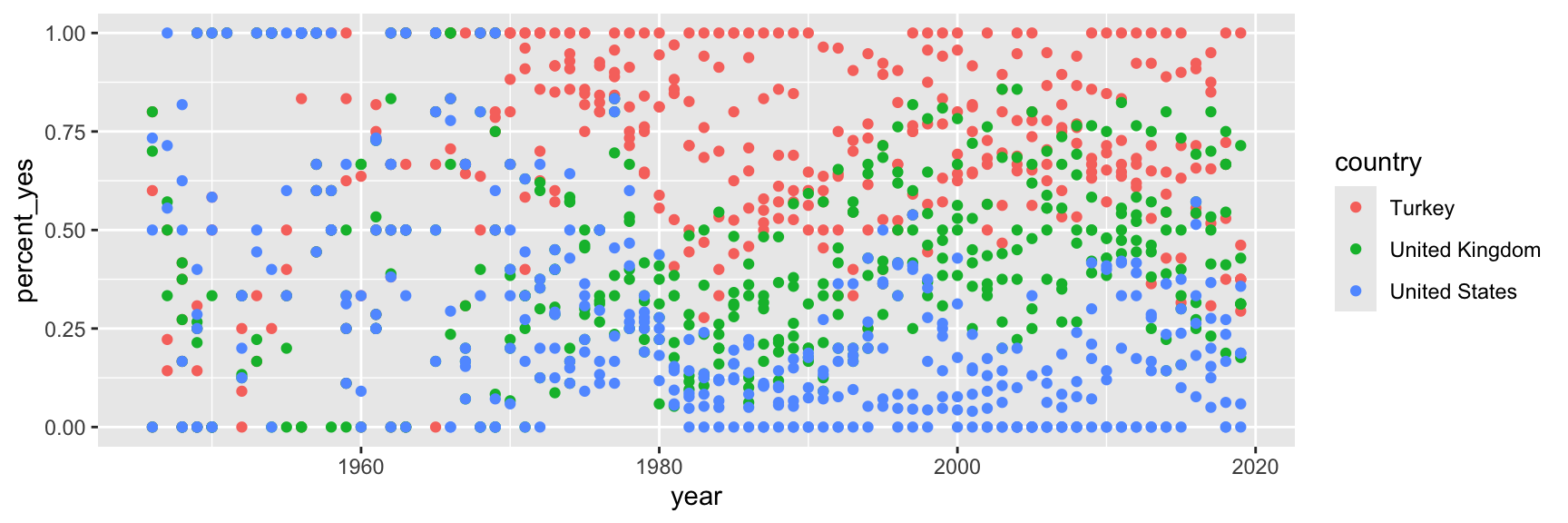
Step 5. Map variables to aesthetics
Map country to the color aesthetic
Step 6. Represent data on your canvas
with another geom
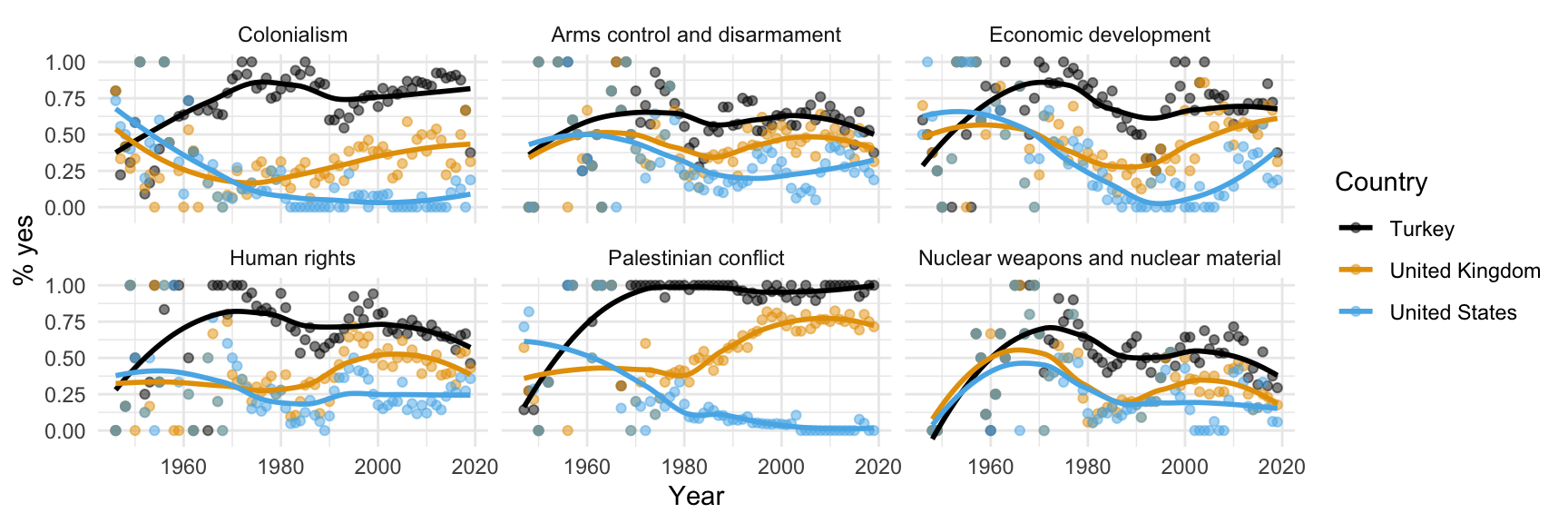
ggplot(us_uk_tr_votes, aes(x = year, y = percent_yes, color = country)) +
geom_point() +
geom_smooth()`geom_smooth()` using method = 'loess' and formula = 'y ~ x'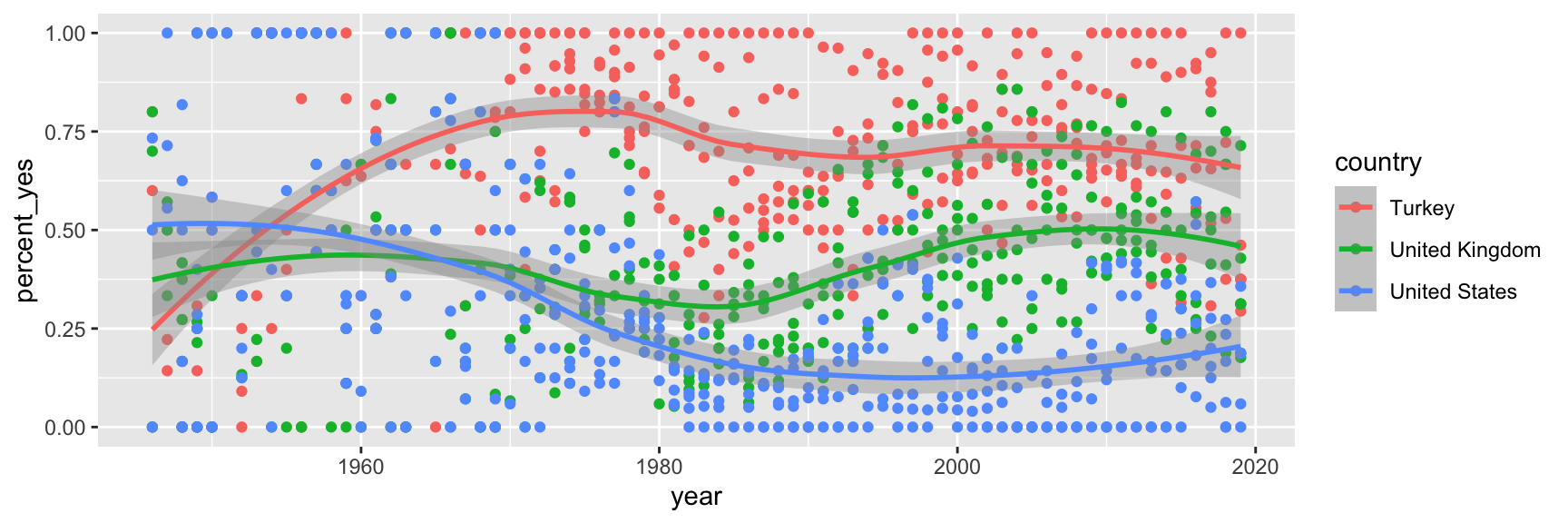
Step 7. Split plot into facets
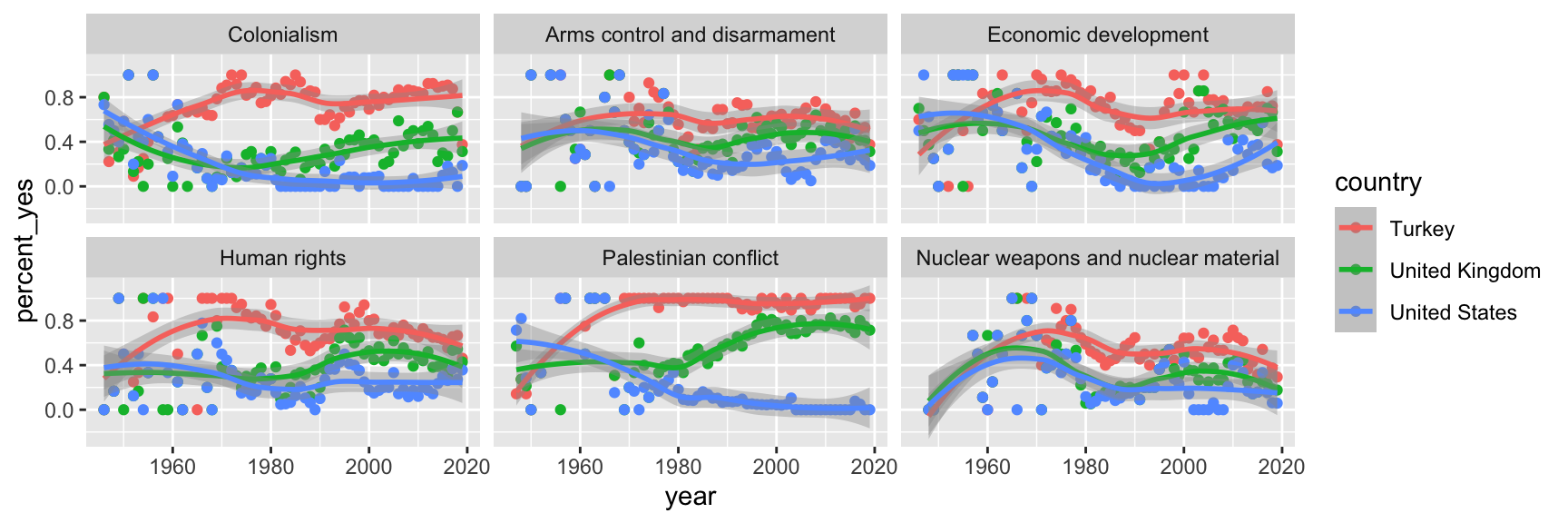
Step 8. Use a different color scale
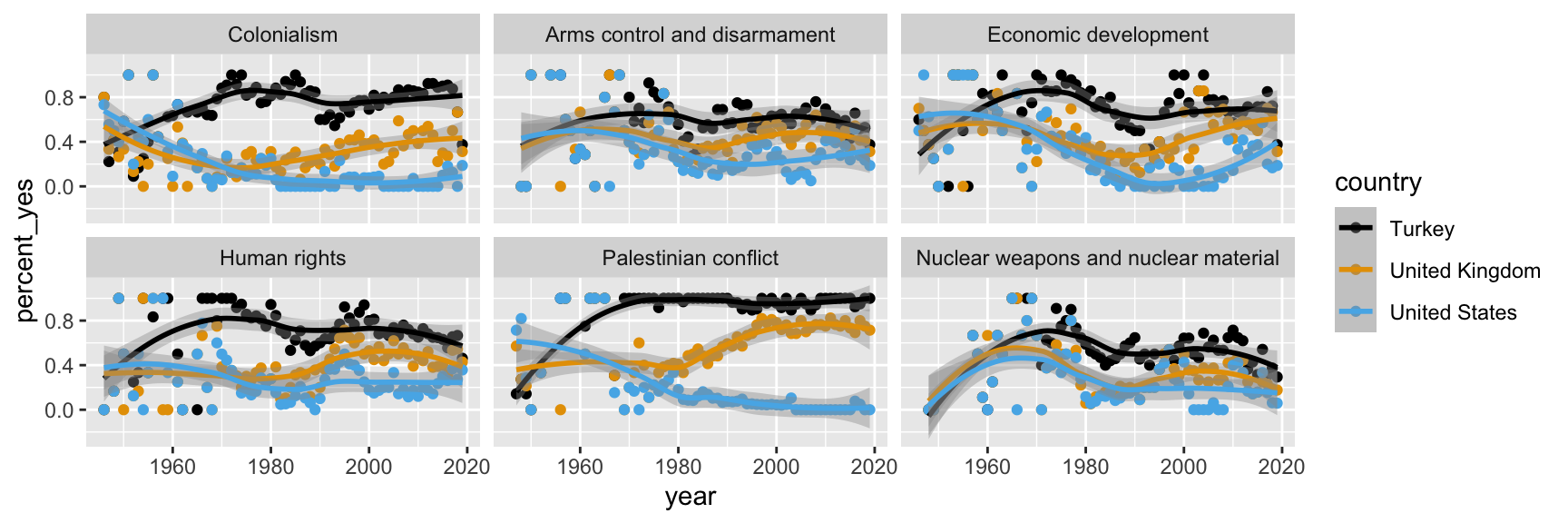
Step 9. Apply a different theme
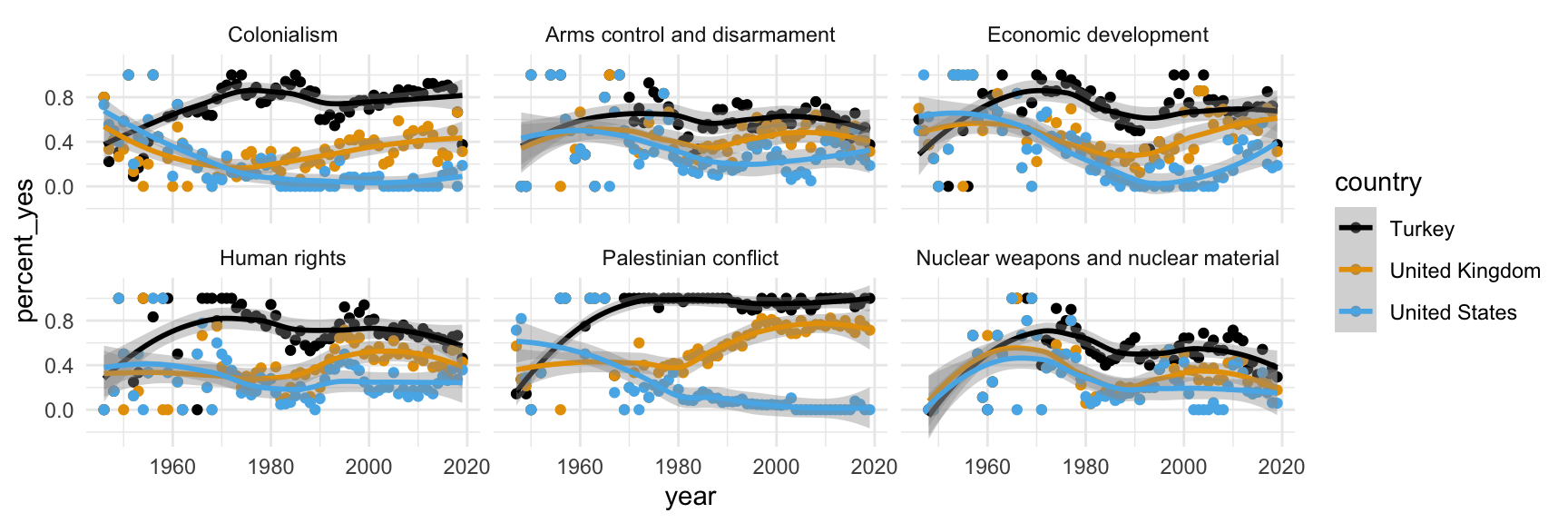
Step 10. Add labels
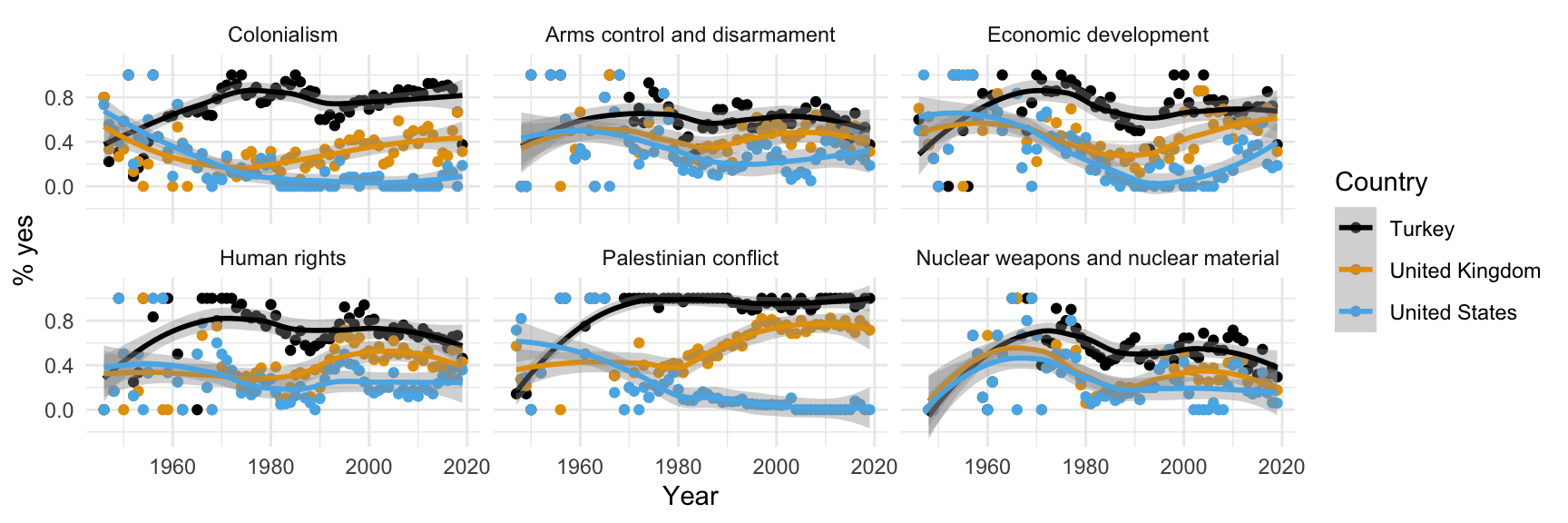
Step 11. Set transparency of points
with alpha
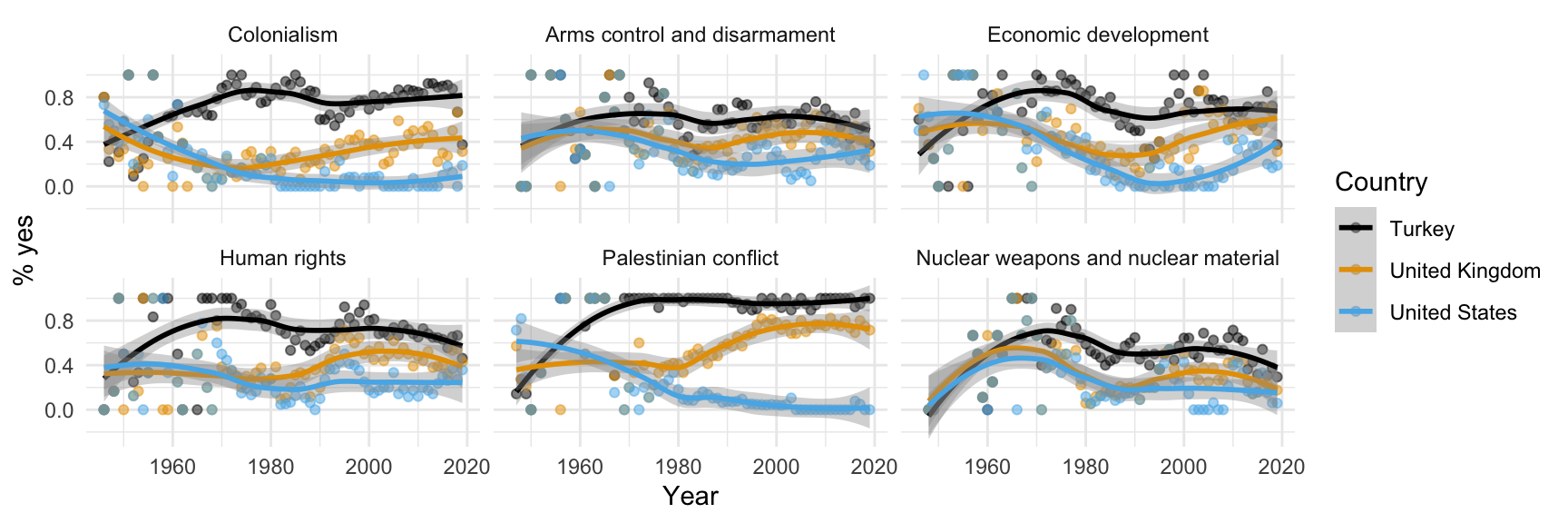
Step 12. Hide standard errors of curves
with se = FALSE
Data viz with ggplot is like building a cake

The commands are the layers of sponge, and the plus signs are the icing. Don’t forget the icing!
Grammar of graphics
We built a plot layer-by-layer
- just like described in the book The Grammar of Graphics and
- implemented in the ggplot2 package, the data visualization package of the tidyverse.

