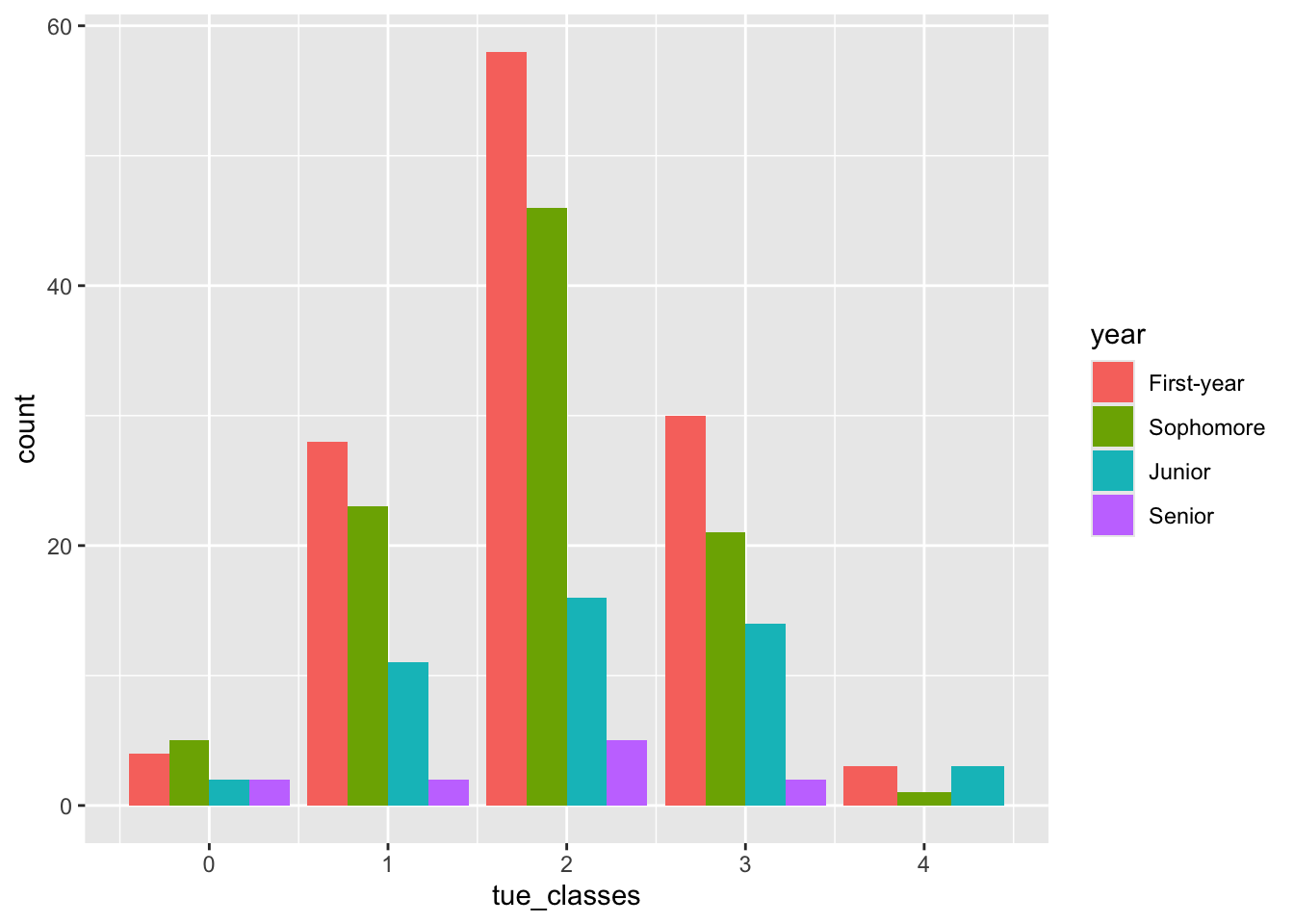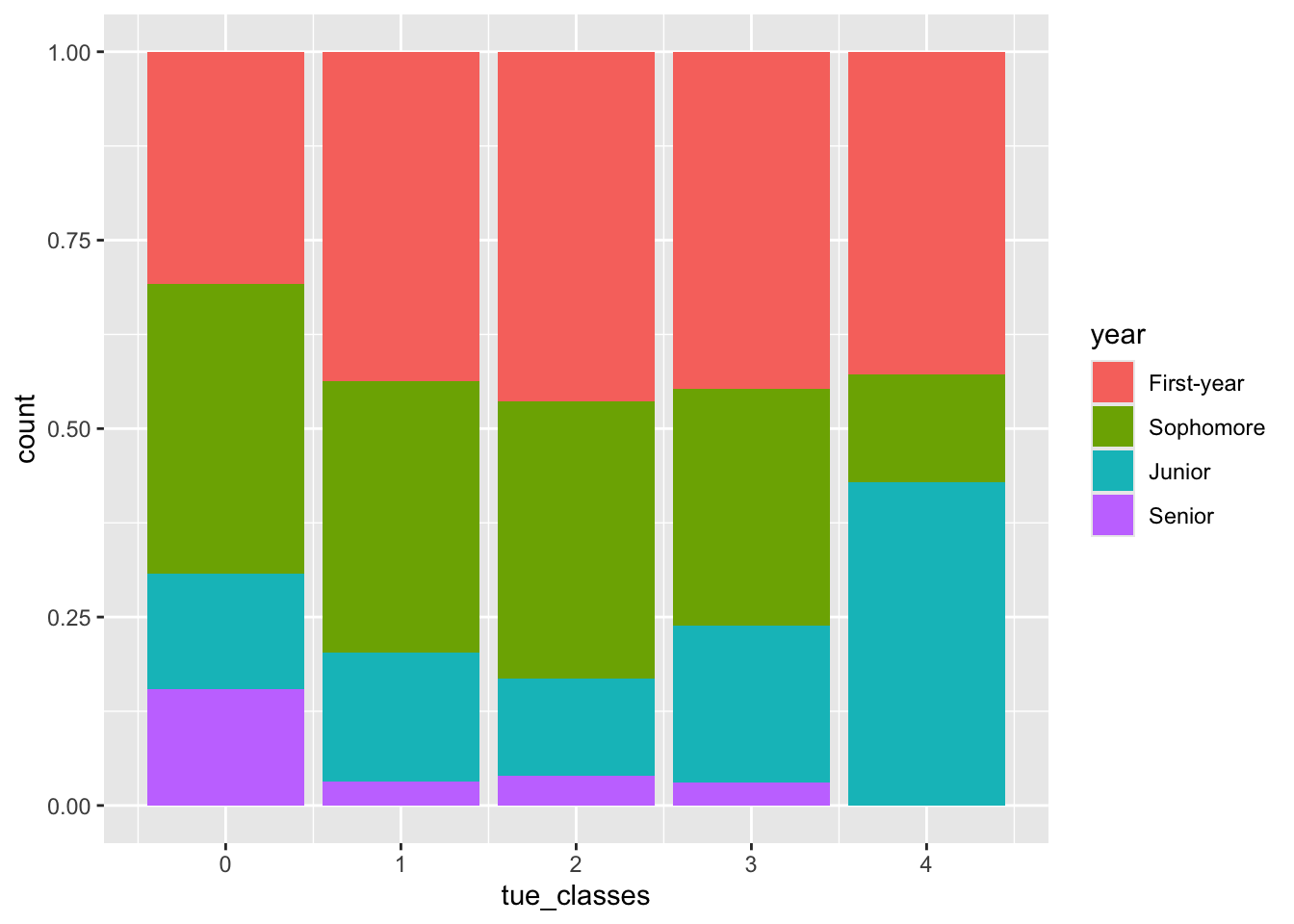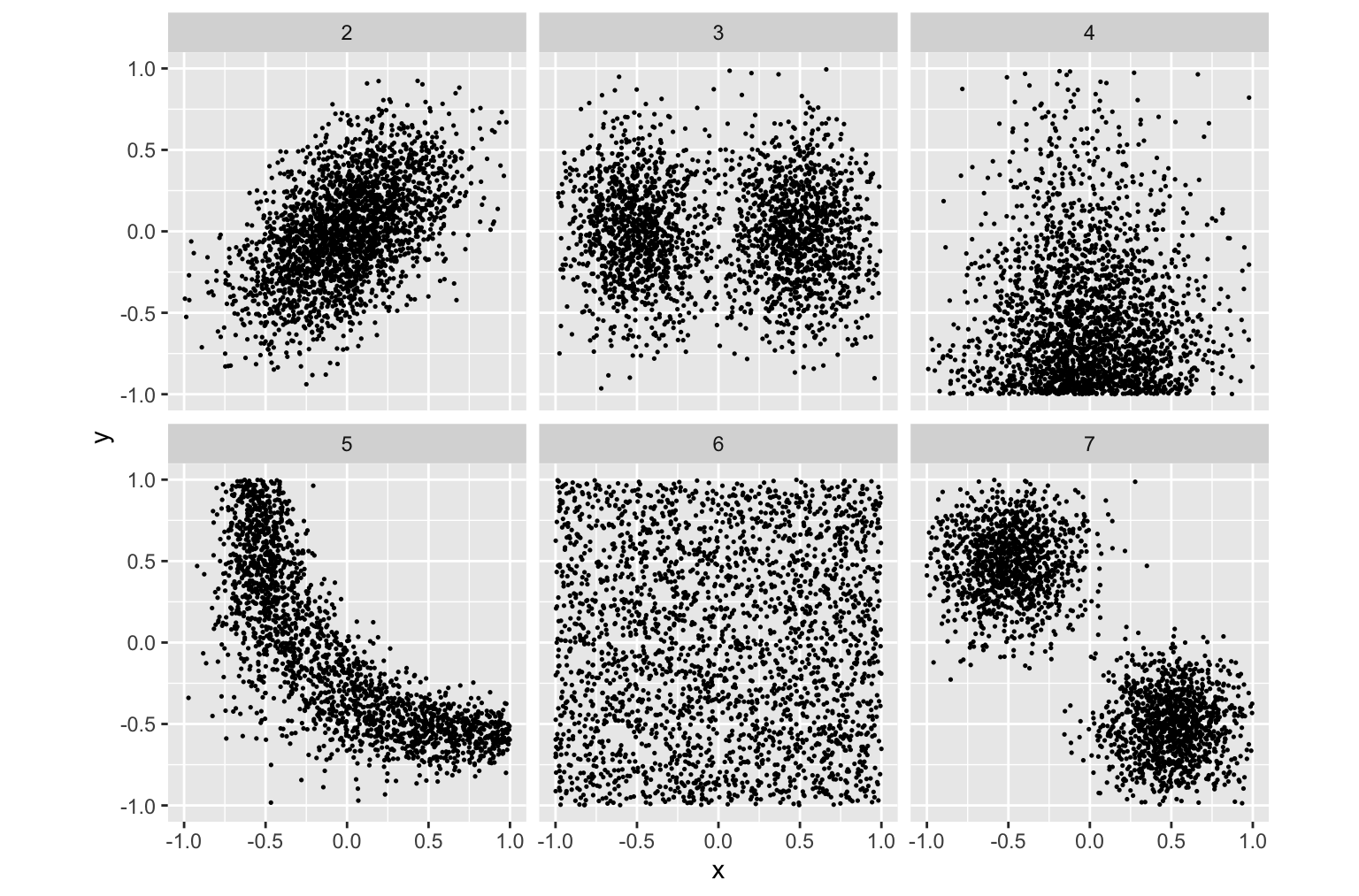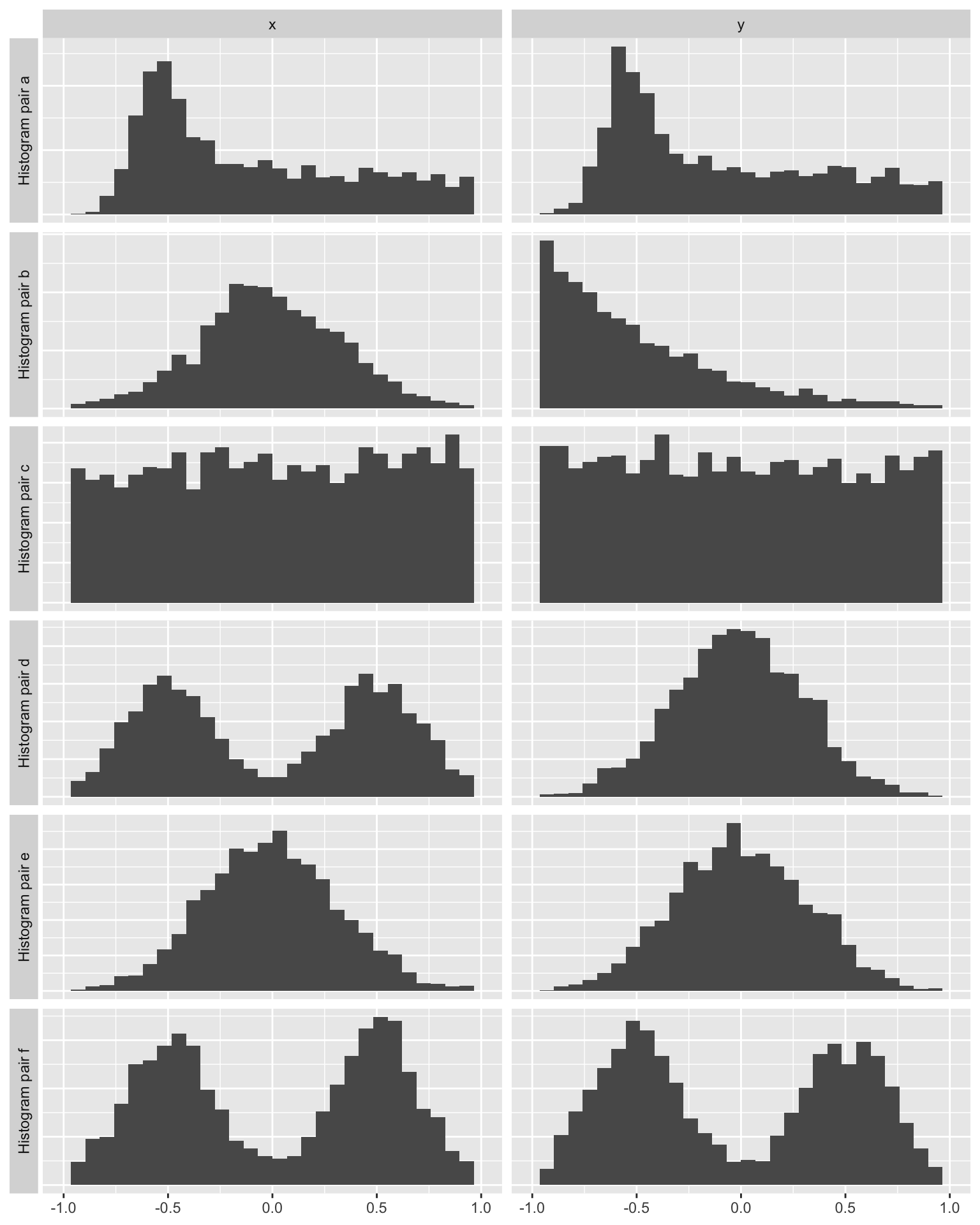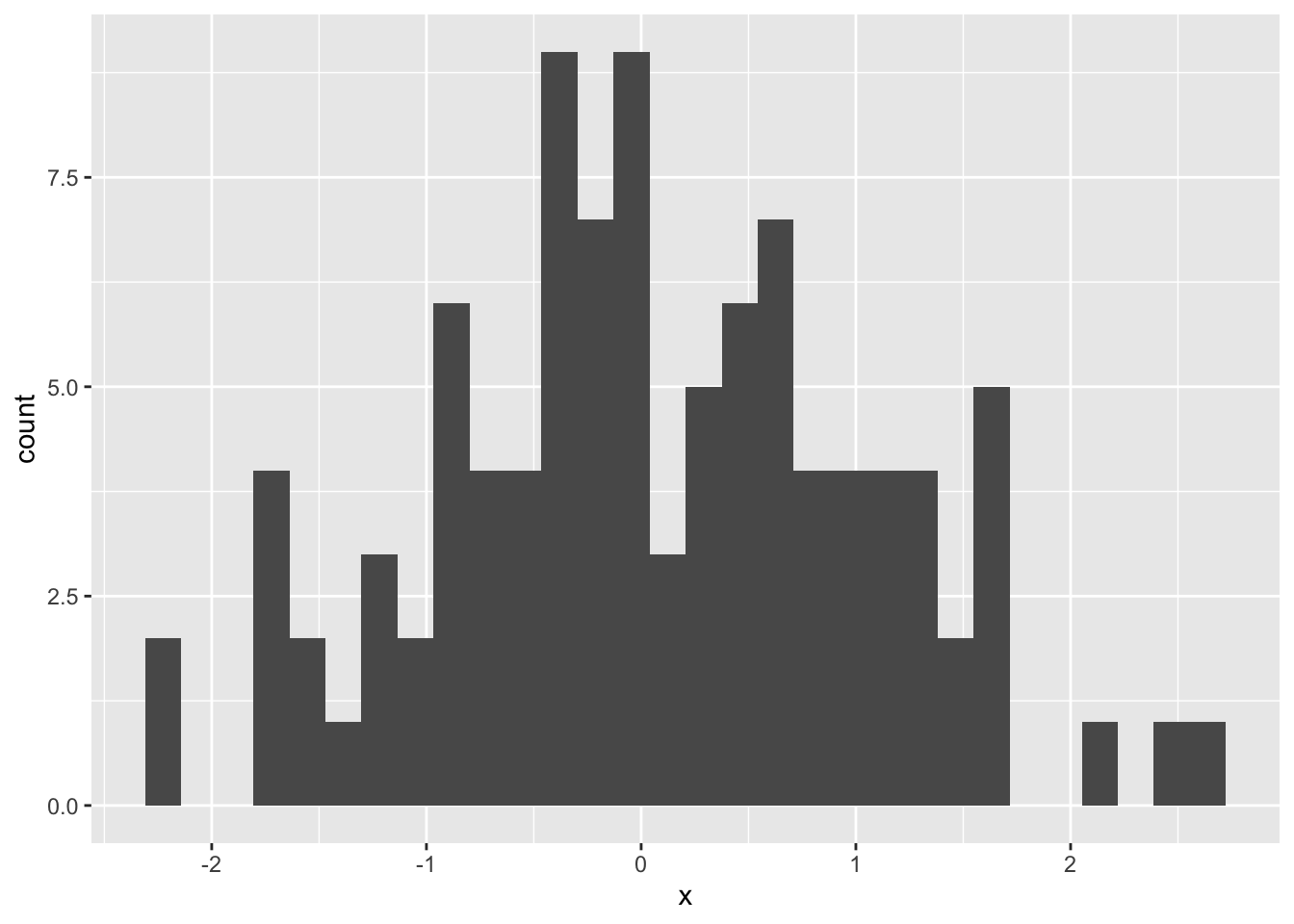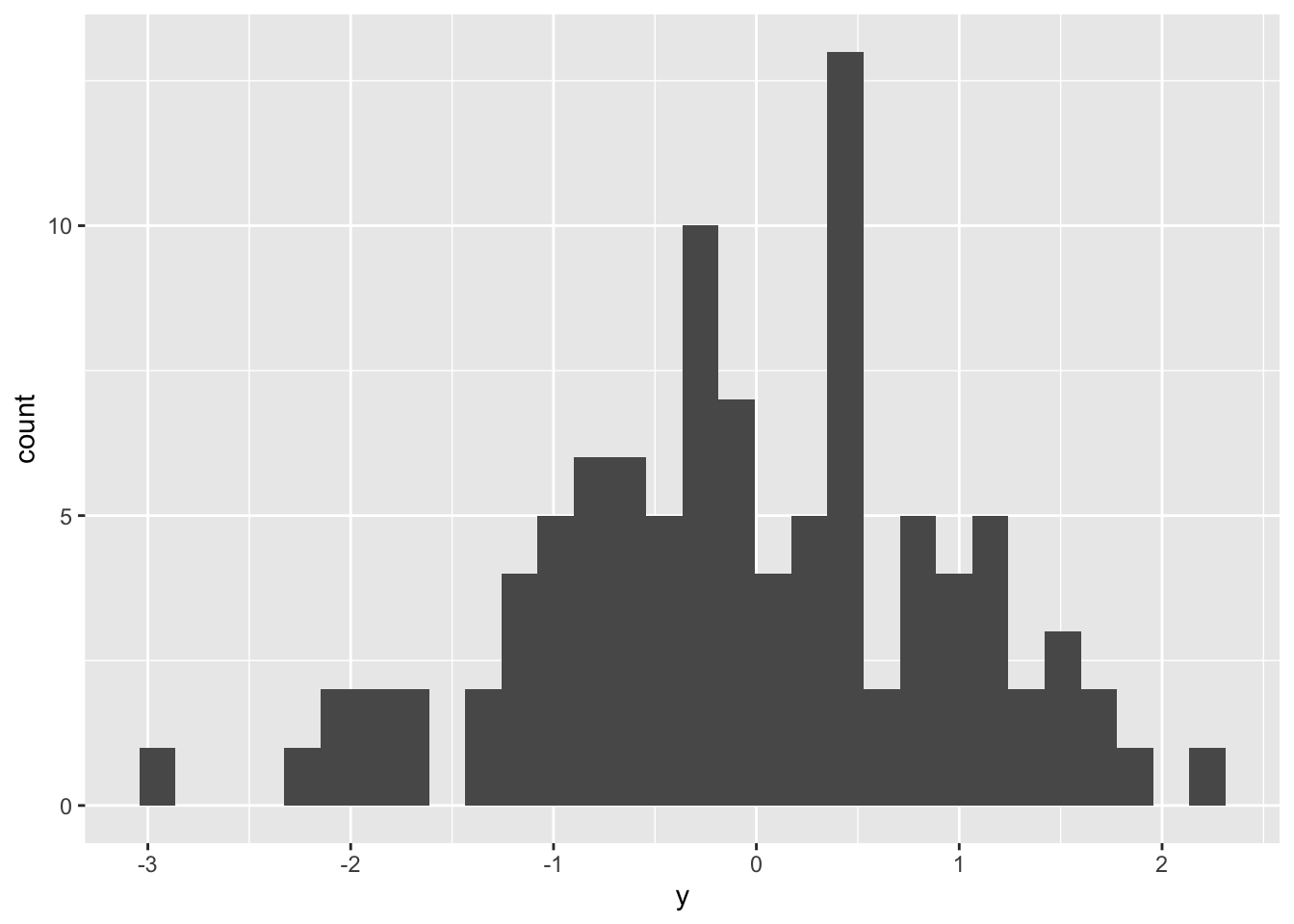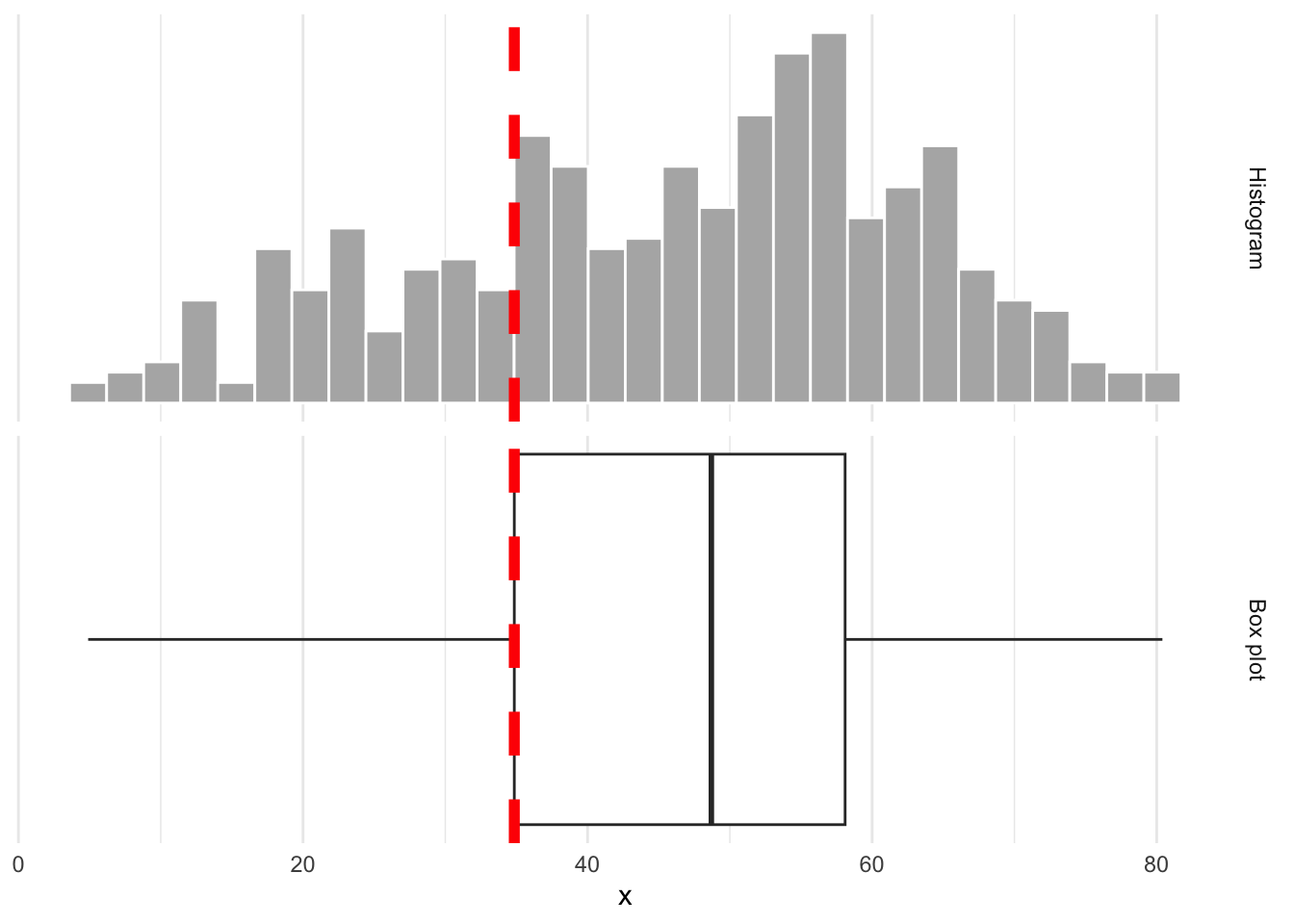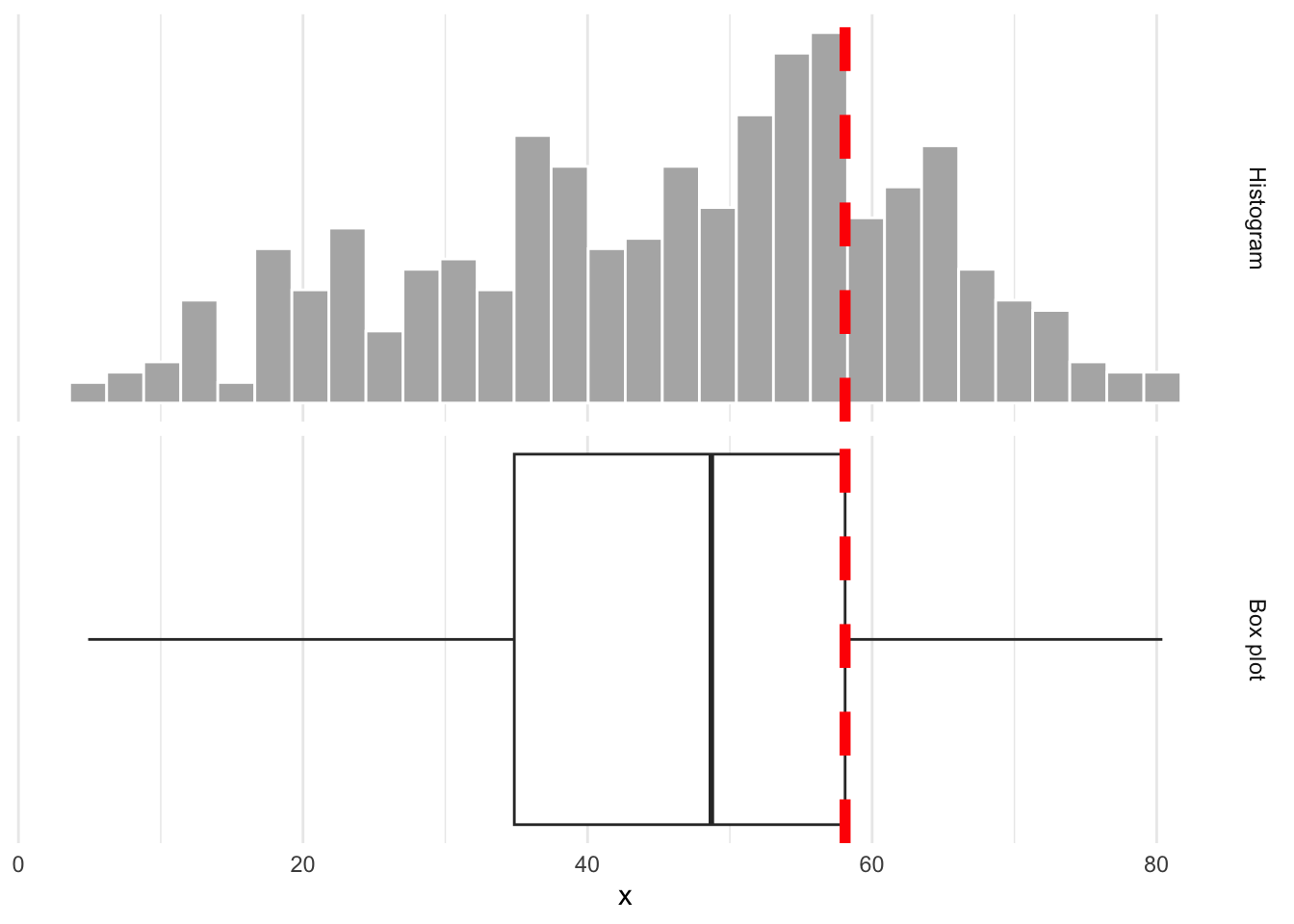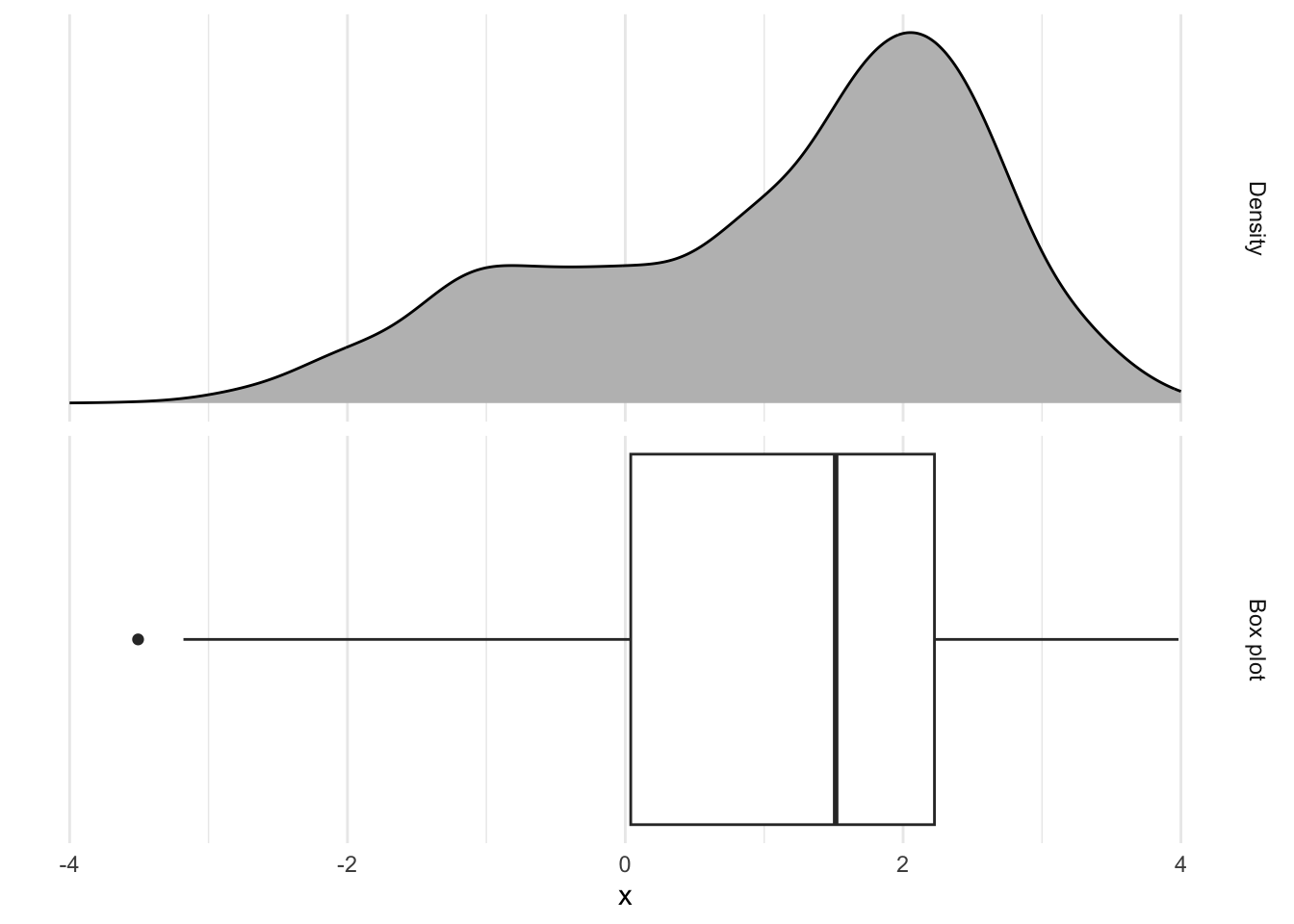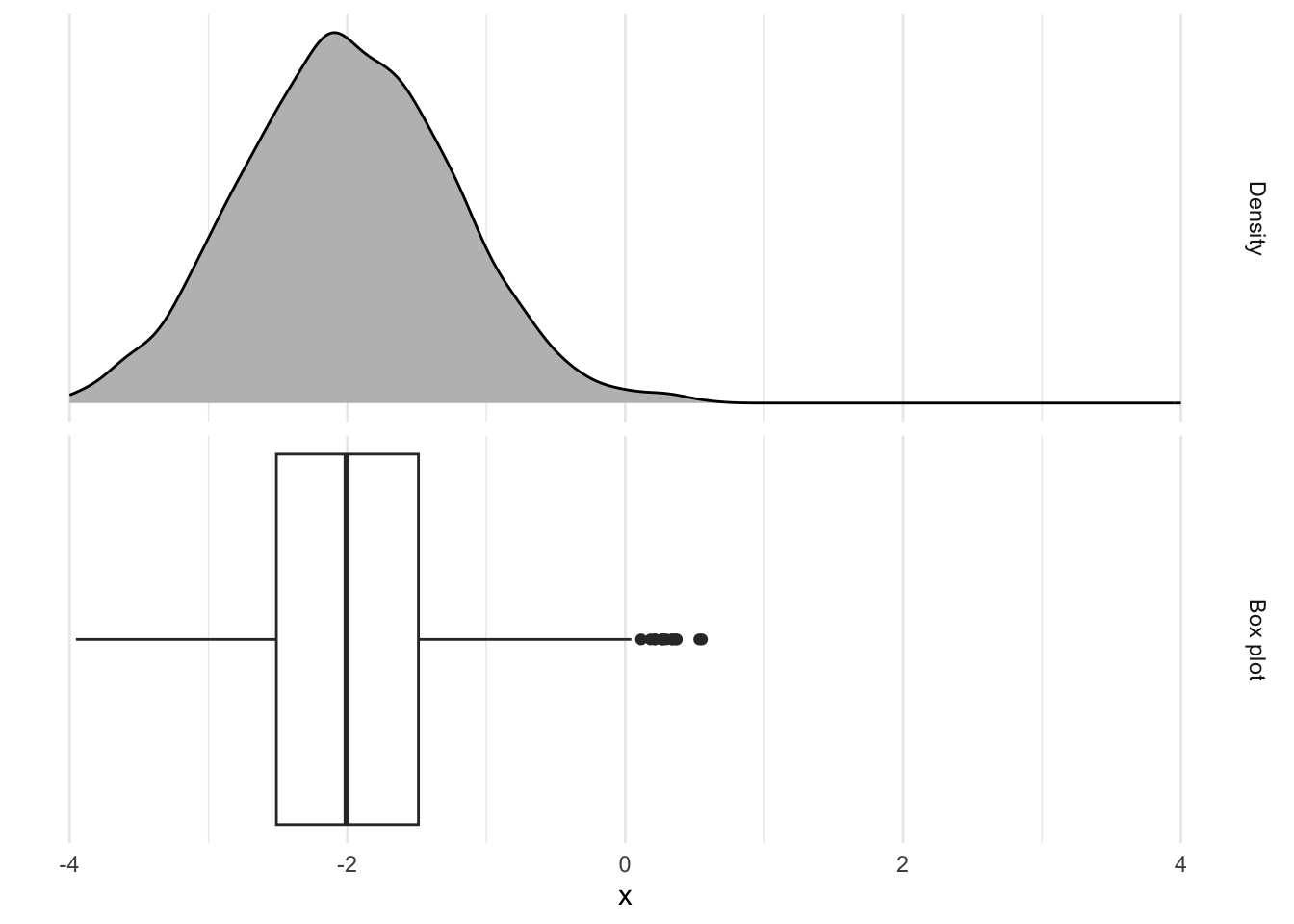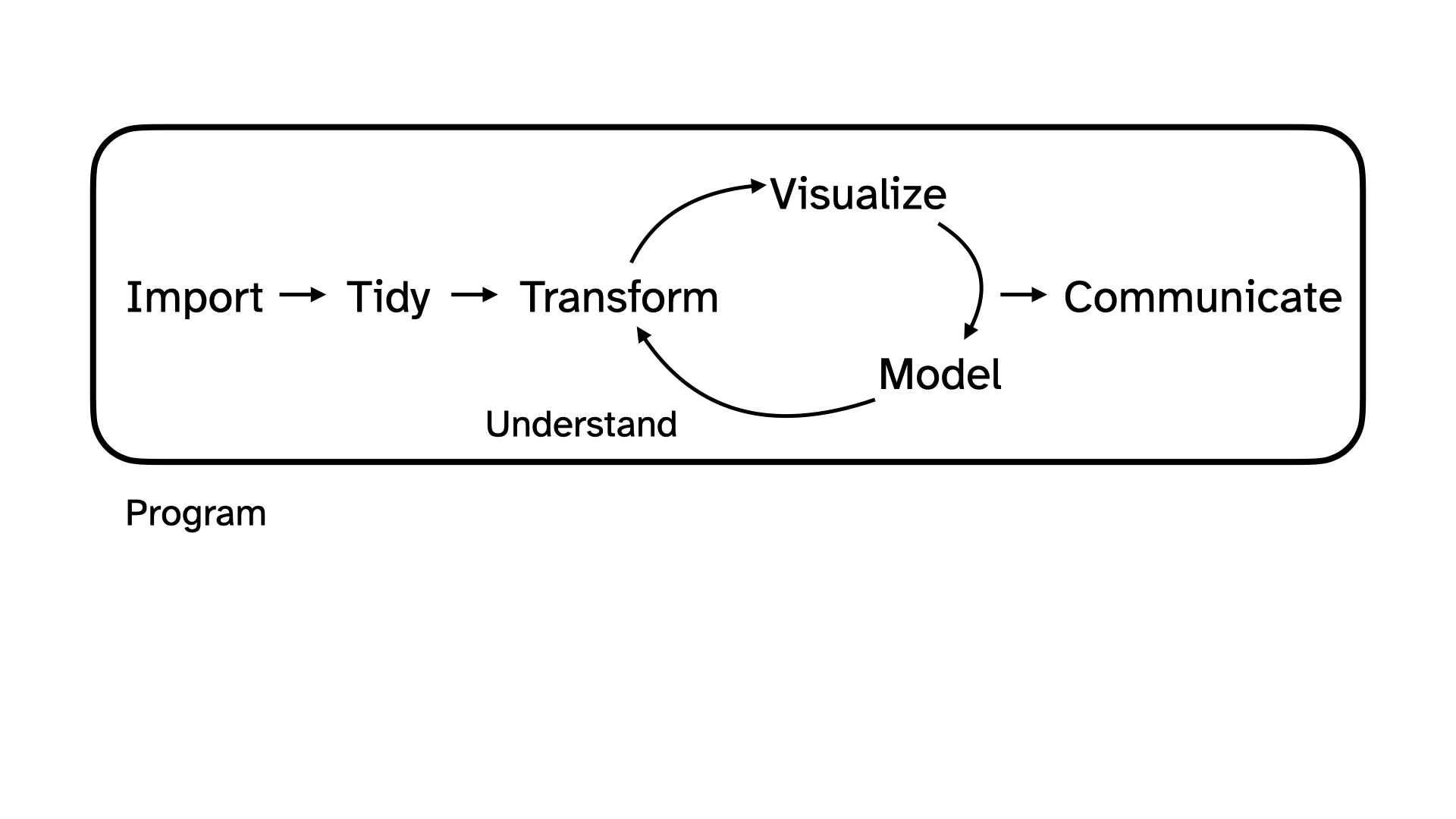
Rows: 276 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): Timestamp, How many classes do you have on Tuesdays?, What year are...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# A tibble: 276 × 3
Timestamp How many classes do you have on Tues…¹ `What year are you?`
<chr> <chr> <chr>
1 2/9/2026 11:03:46 3 First-year
2 2/9/2026 11:29:24 2 Sophomore
3 2/9/2026 11:33:44 2 Sophomore
4 2/9/2026 11:33:48 2 Sophomore
5 2/9/2026 11:33:56 1 First-year
6 2/9/2026 11:33:56 3 First-year
7 2/9/2026 11:33:58 3 Sophomore
8 2/9/2026 11:34:07 3 Sophomore
9 2/9/2026 11:34:13 2 First-year
10 2/9/2026 11:34:20 3 Junior
# ℹ 266 more rows
# ℹ abbreviated name: ¹`How many classes do you have on Tuesdays?`