Inference overview
Lecture 24
2026-04-20
Chamber music tonight and tomorrow

- April 20 @ 6PM (Nelson Music Room on East);
- April 21 @ 7:30 PM (Baldwin);
- Several past, present, and future(!) students;
- Many bangers and bops, including JZ favorites by Ravel and Fauré.
Spread the word! Summer WANANA!
- Summer Session 1
- May 13 - June 25
- Katie Solarz!

- Summer Session 2
- June 29 - August 10
- Josh Lim!

Sorry gang
What the summer kids will get:

What you got:

Point estimation (roman letters, hats!)
We estimate \(\beta_0\) and \(\beta_1\) with the coefficients of the best fit line:
\[ \hat{y}=b_0+b_1x. \]
“Best” means “least squares.” We pick the estimates so that the sum of squared residuals is as small as possible. Play around!
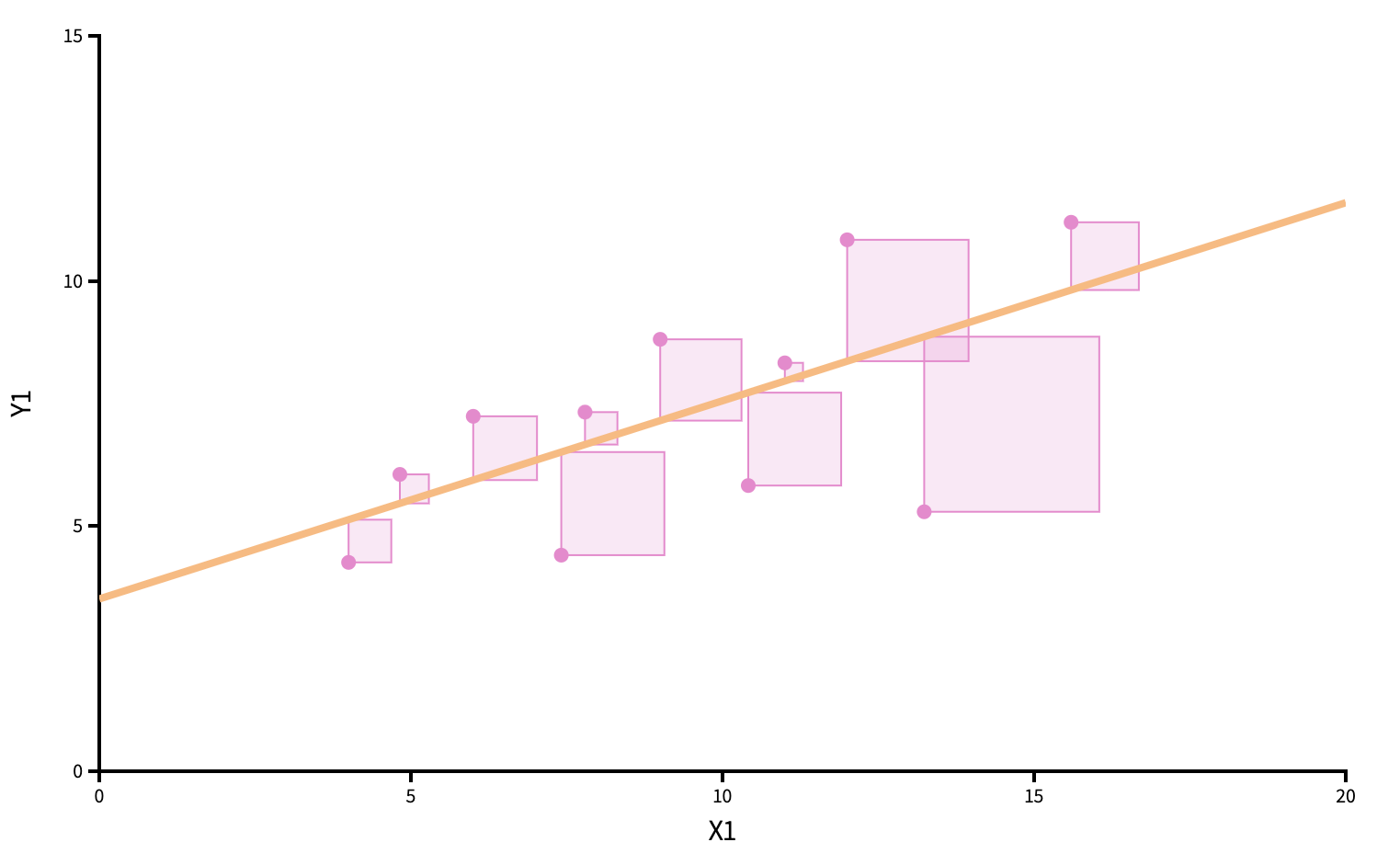
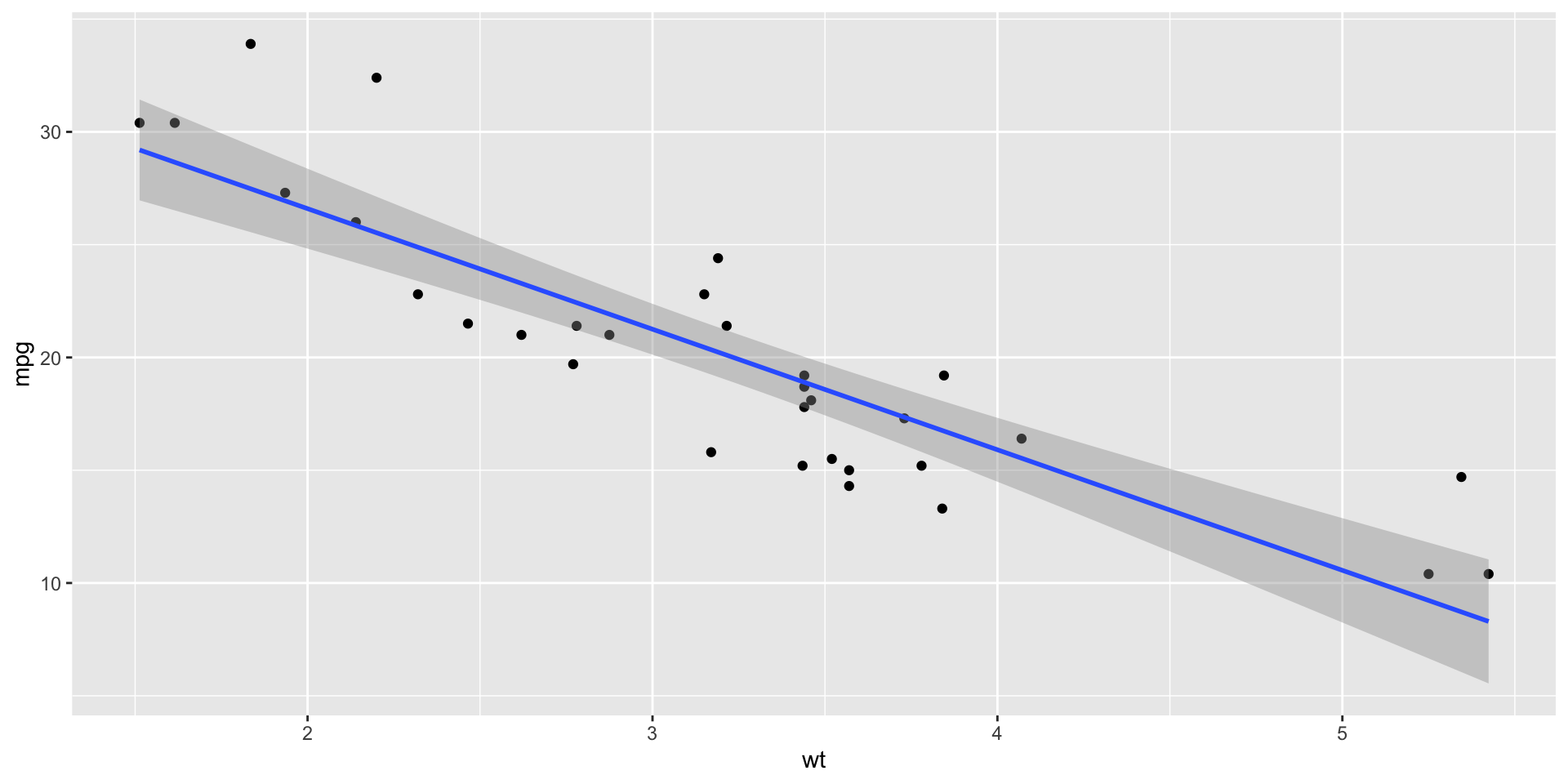
Point estimation
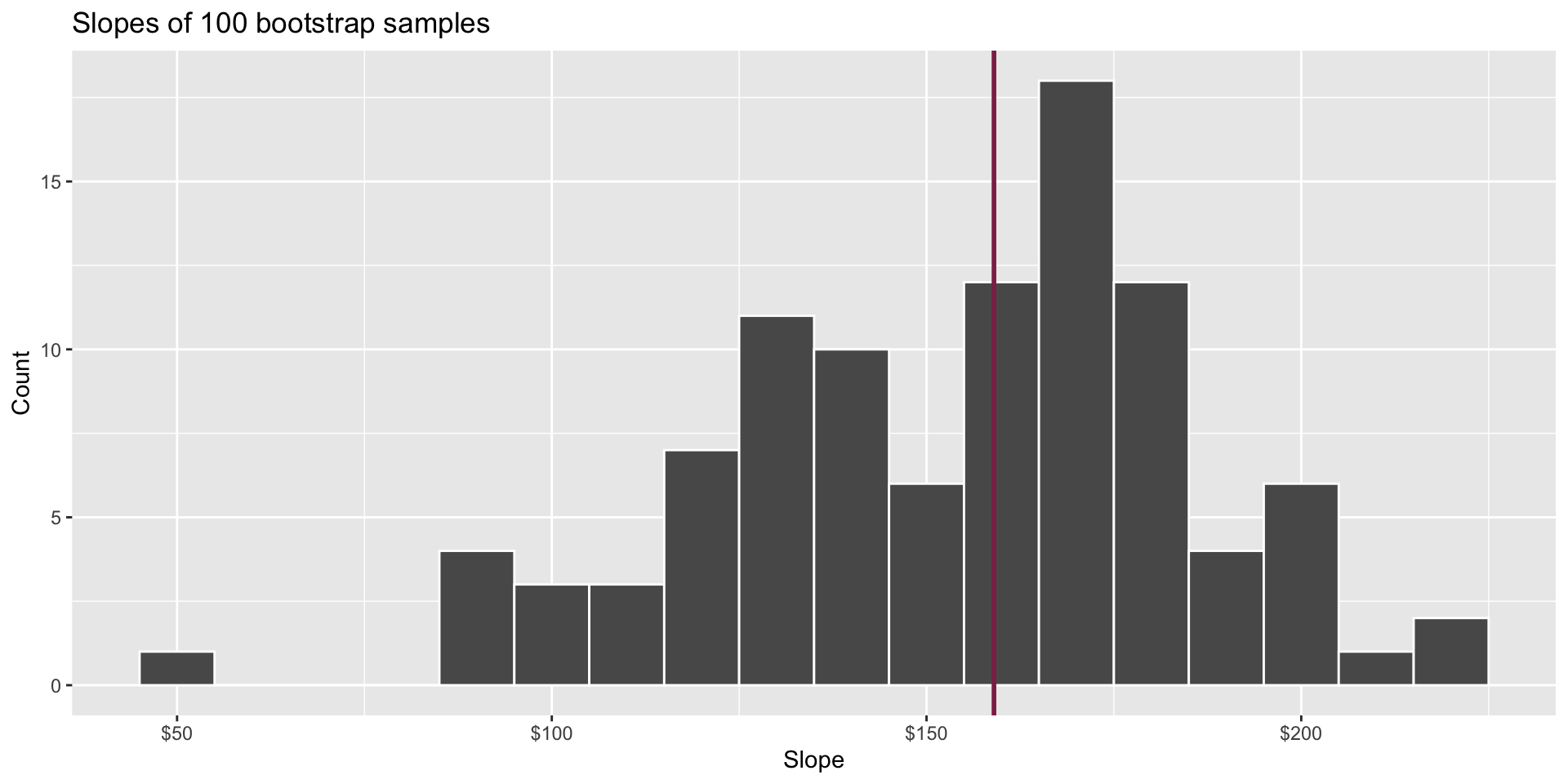
Bootstrap distribution
This histogram displays variation in the slope estimate across alternative datasets.
- Large spread >> high uncertainty;
- Small spread >> lower uncertainty.
Confidence interval
Pick a range that swallows up a large % of the histogram:
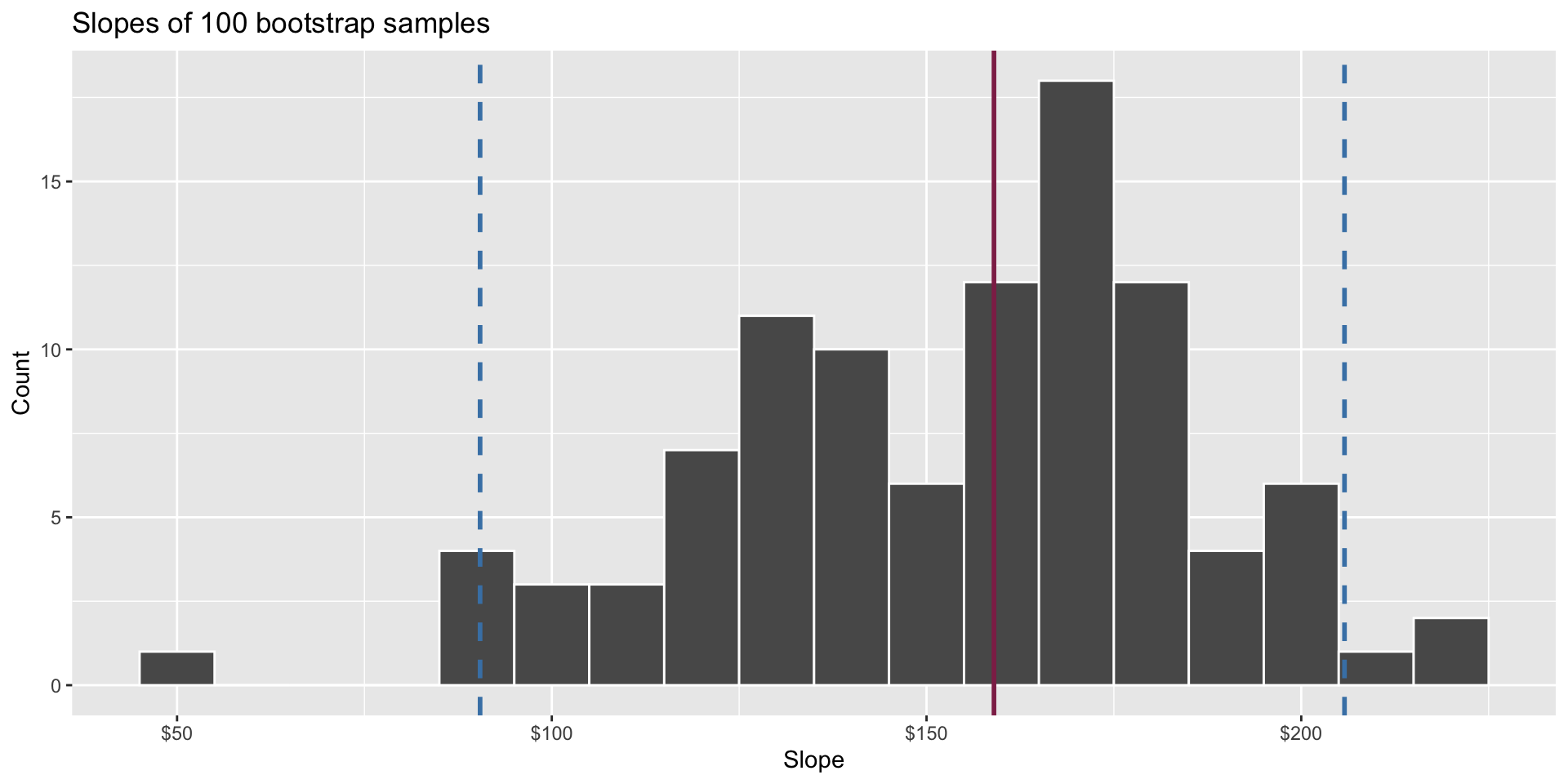
We use quantiles (think IQR) but there are other ways.
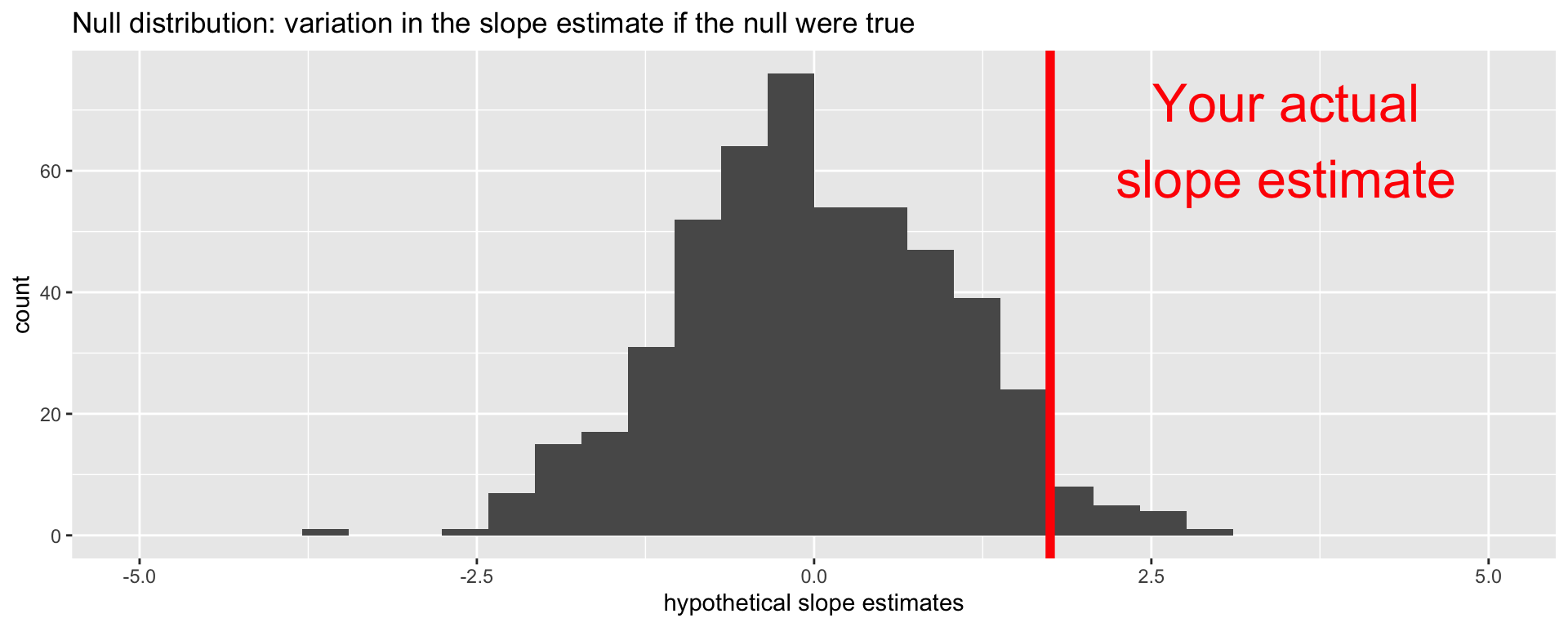
Null distribution
If the null happened to be true, how would we expect our results to vary across datasets? We can use simulation to answer this:
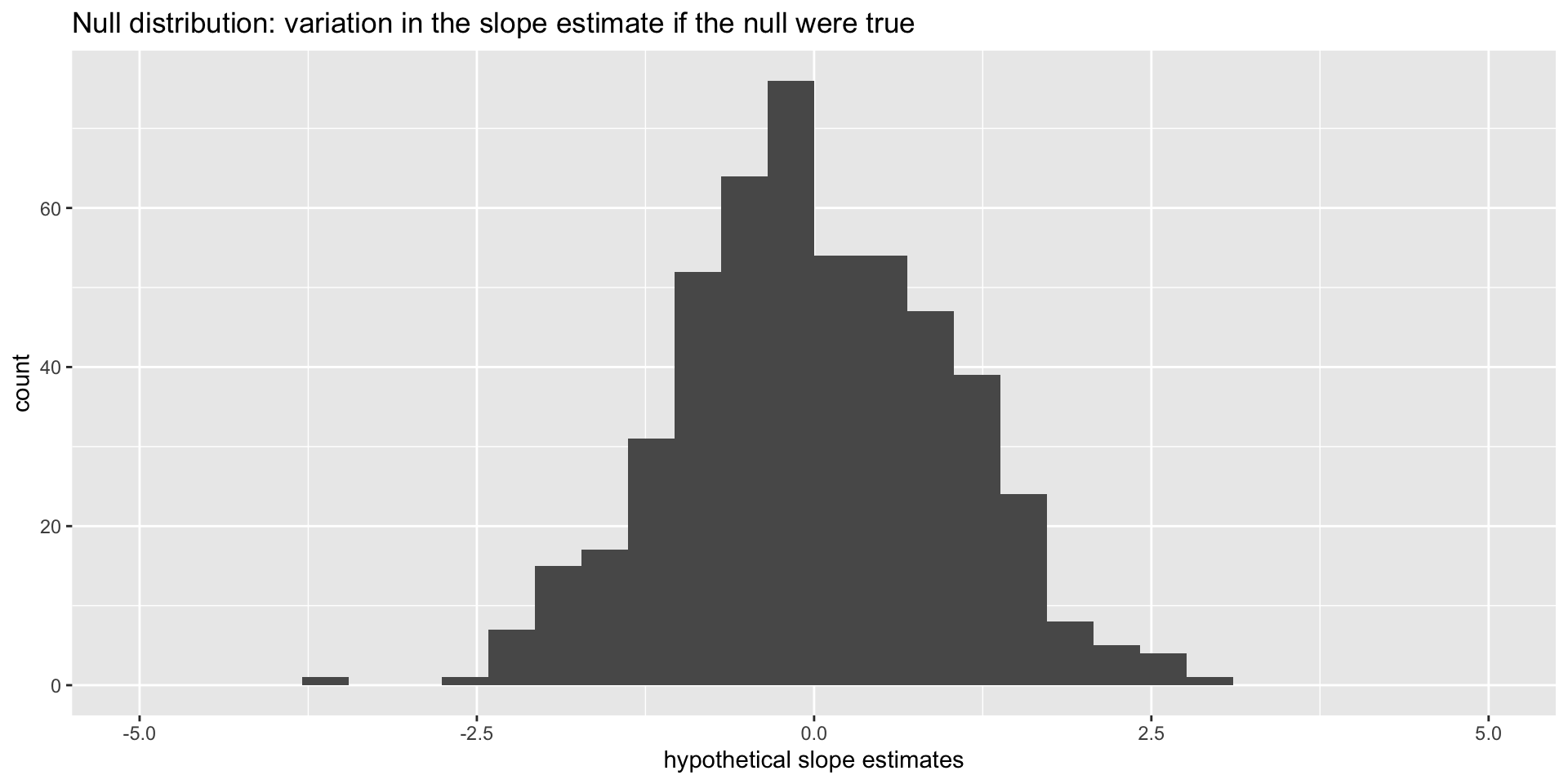
This is how the world should look if the null is true.
Null distribution versus reality
Locate the actual results of your actual data analysis under the null distribution. Are they in the middle? Are they in the tails?
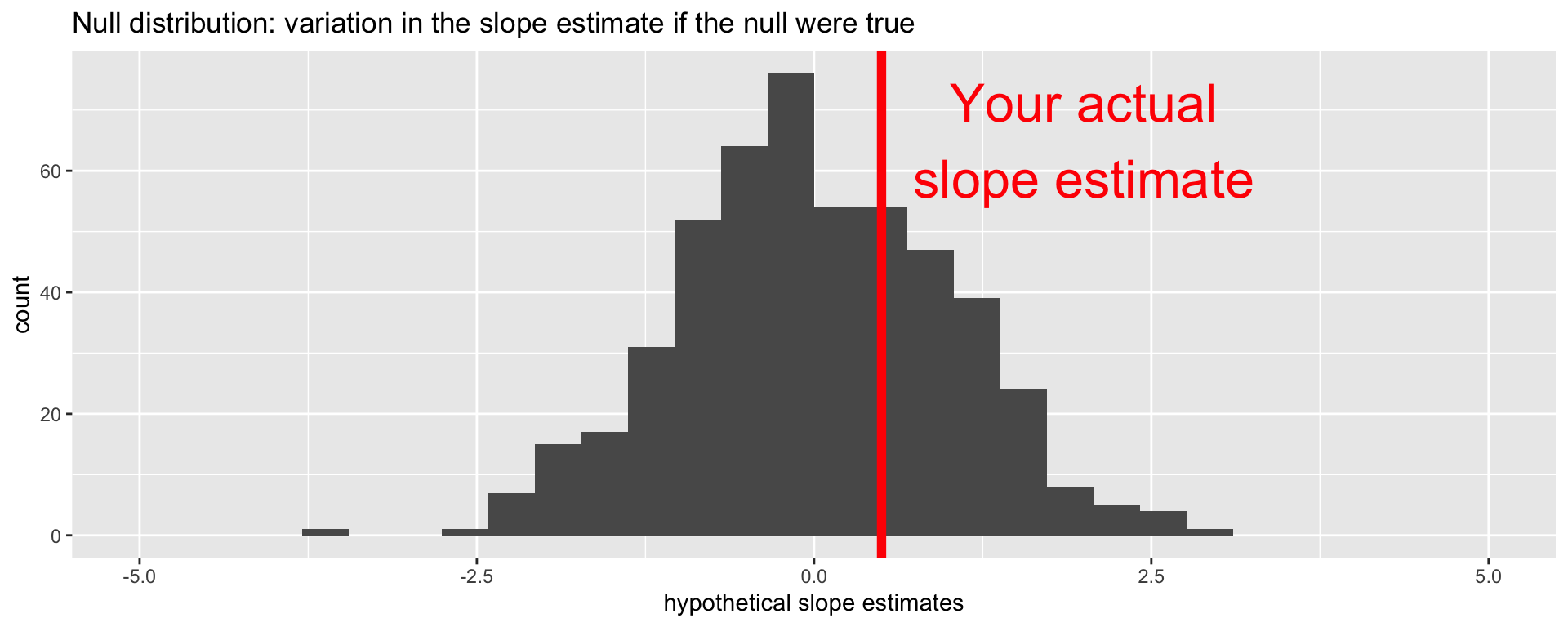
Are these results in harmony or conflict with the null?
Null distribution versus reality
Locate the actual results of your actual data analysis under the null distribution. Are they in the middle? Are they in the tails?
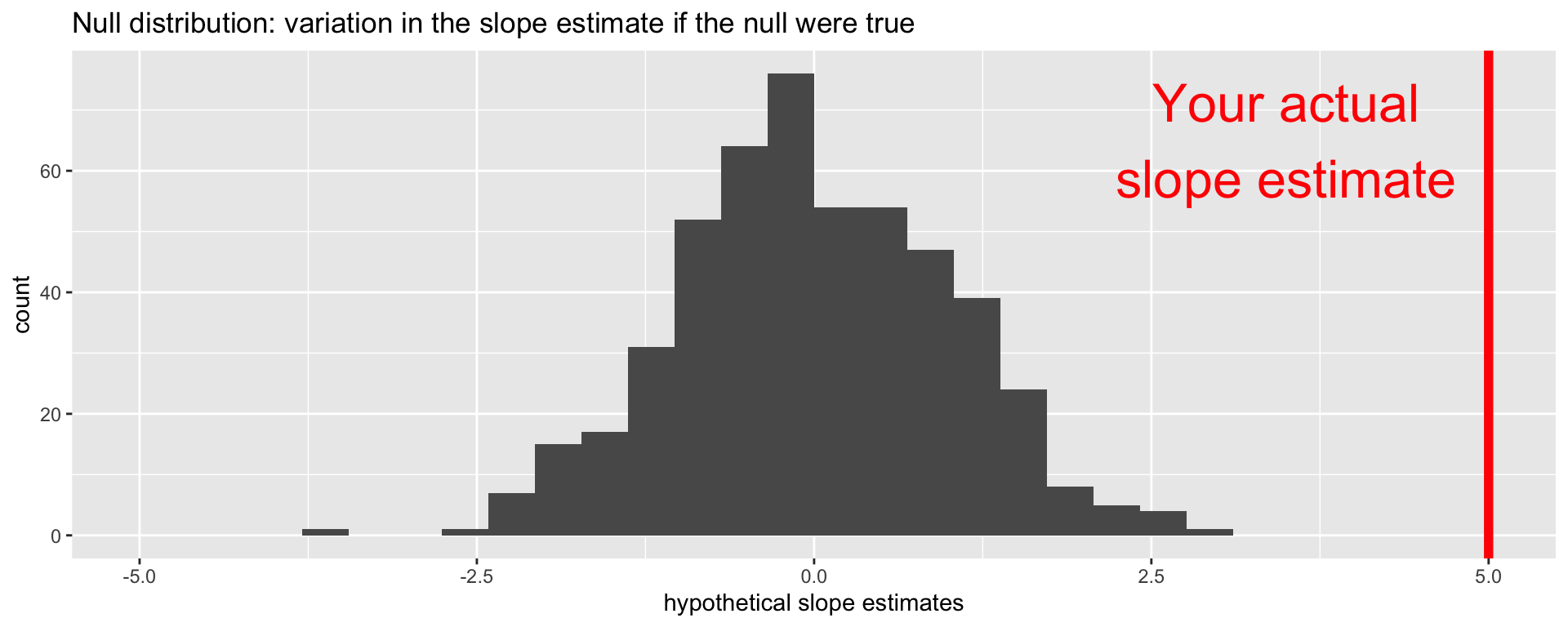
Are these results in harmony or conflict with the null?
Null distribution versus reality
Locate the actual results of your actual data analysis under the null distribution. Are they in the middle? Are they in the tails?
Are these results in harmony or conflict with the null?
p-value
p-value is the fraction of the histogram area shaded red:
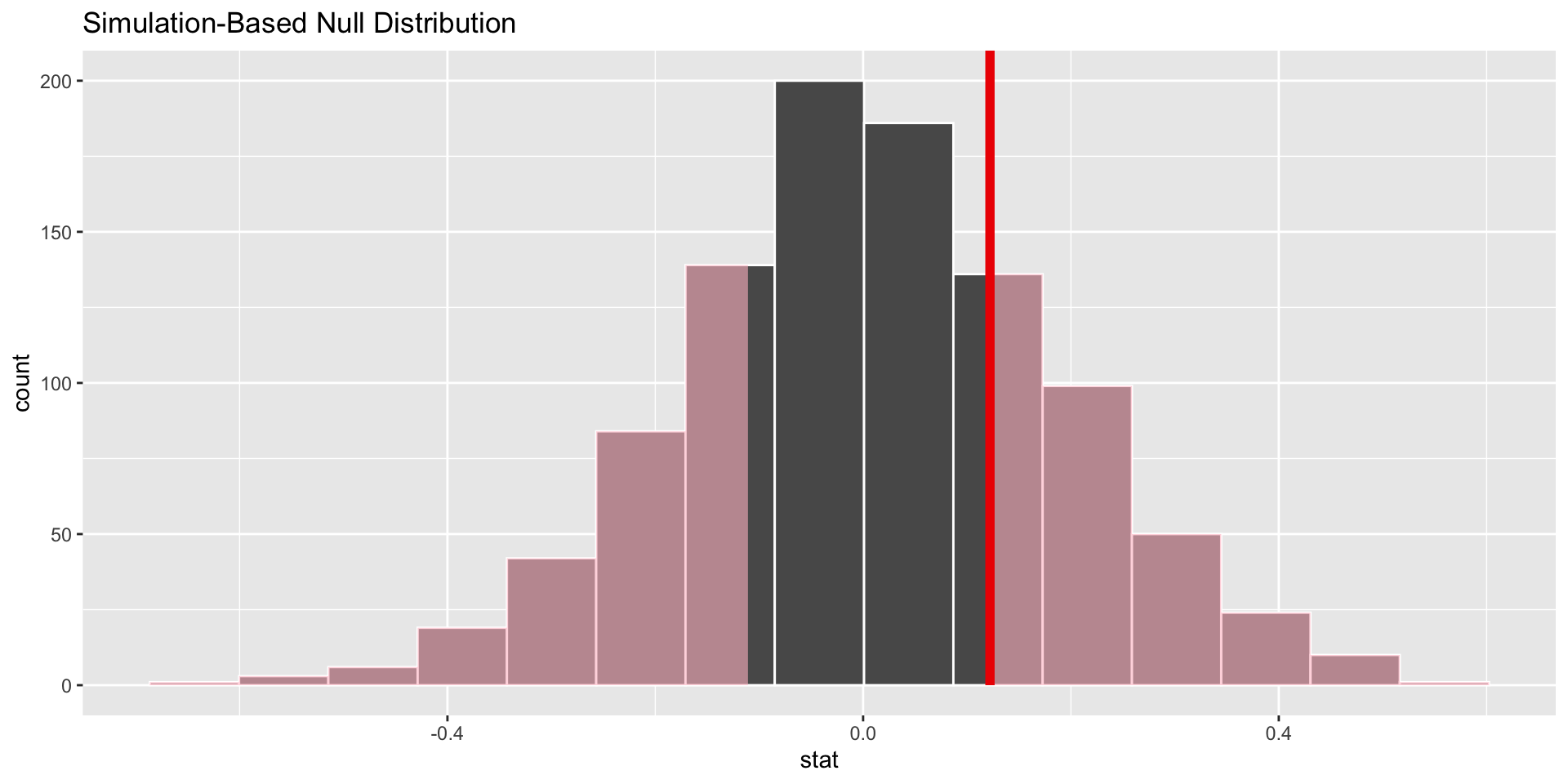
Big ol’ p-value. Null remains plausible
p-value
p-value is the fraction of the histogram area shaded red:
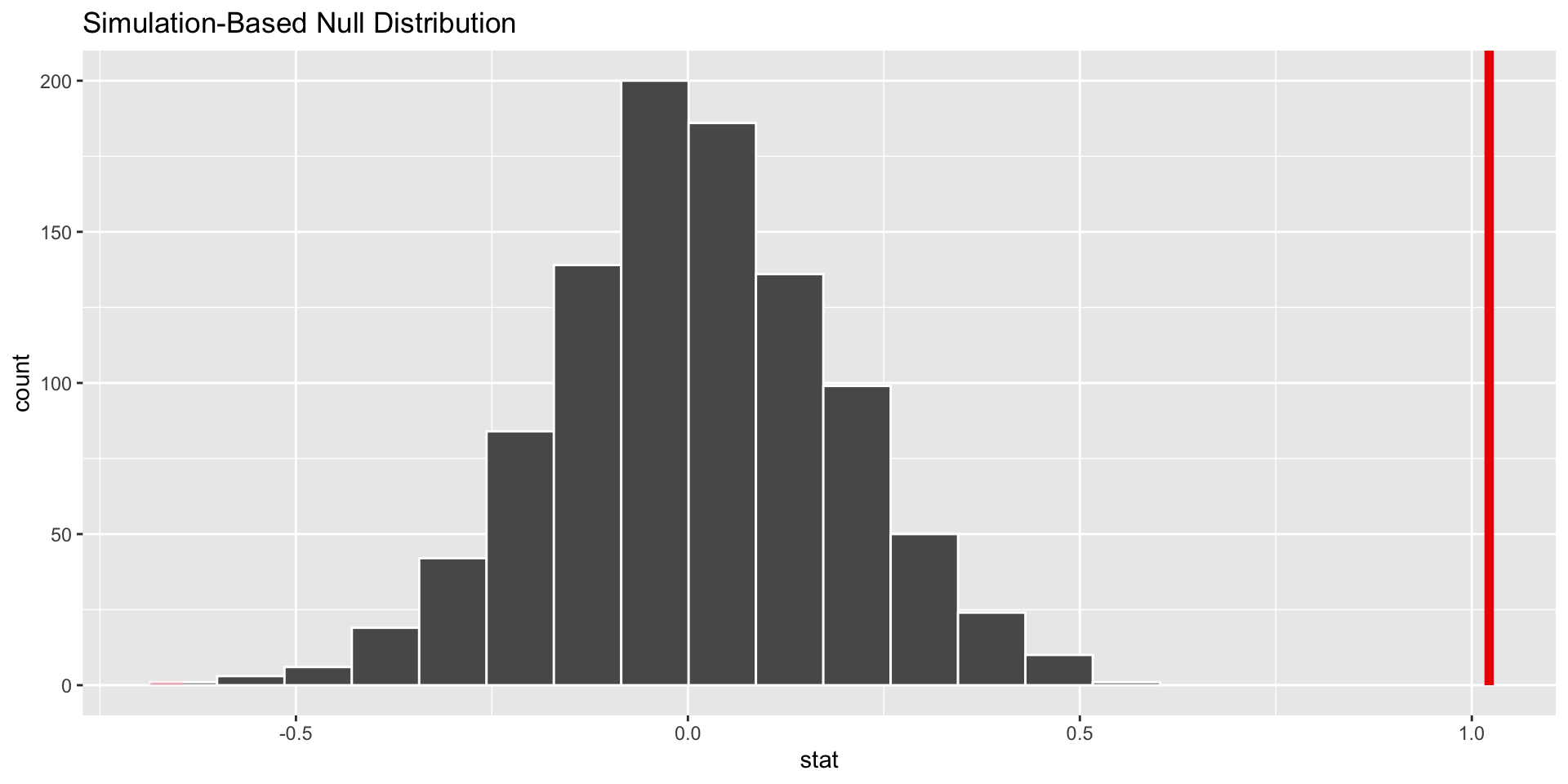
p-value is basically zero. Null looks bogus.
p-value
p-value is the fraction of the histogram area shaded red:
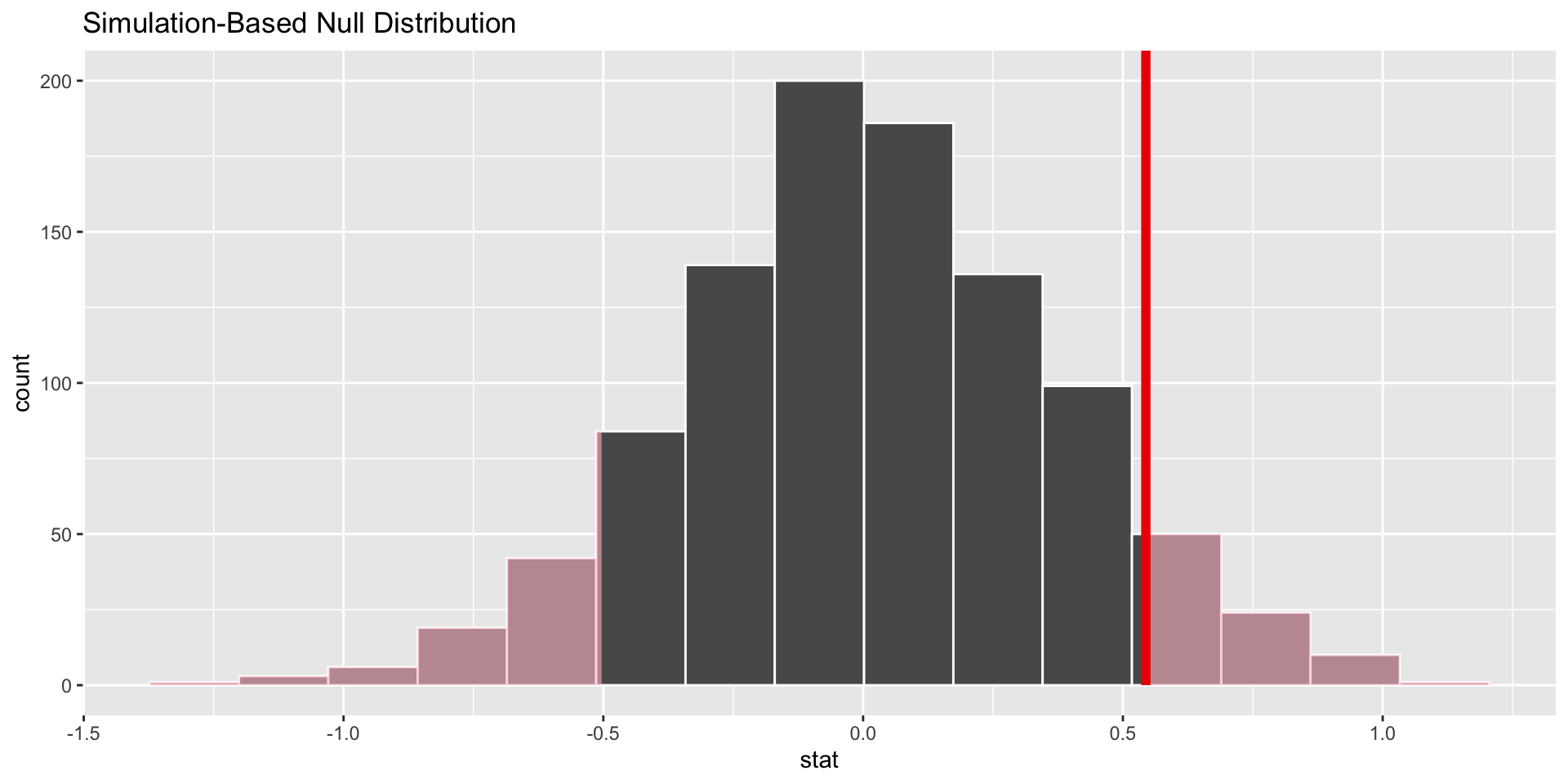
p-value is…kinda small? Null looks…?
What is \(b_1\)?
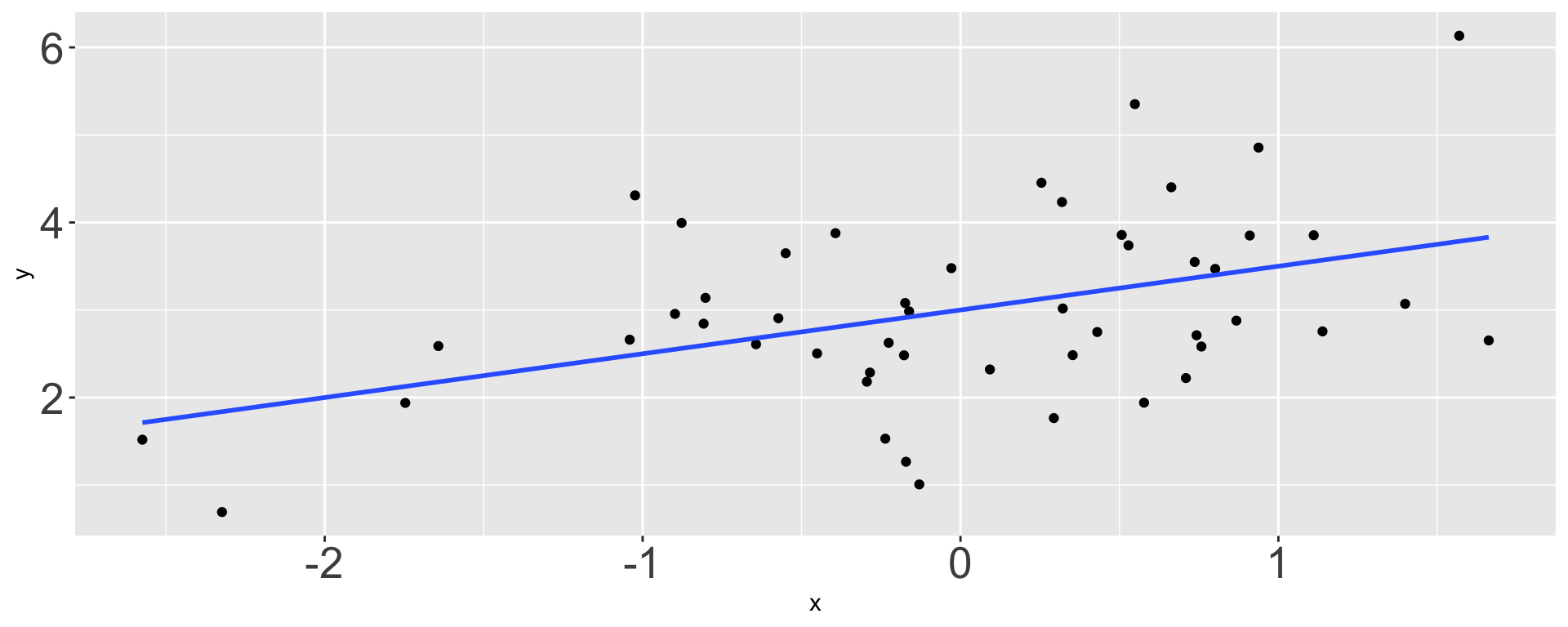
- -1 / 2
- 0
- 1 / 4
- 1 / 2
- 1
- 2
What is \(b_0\)?
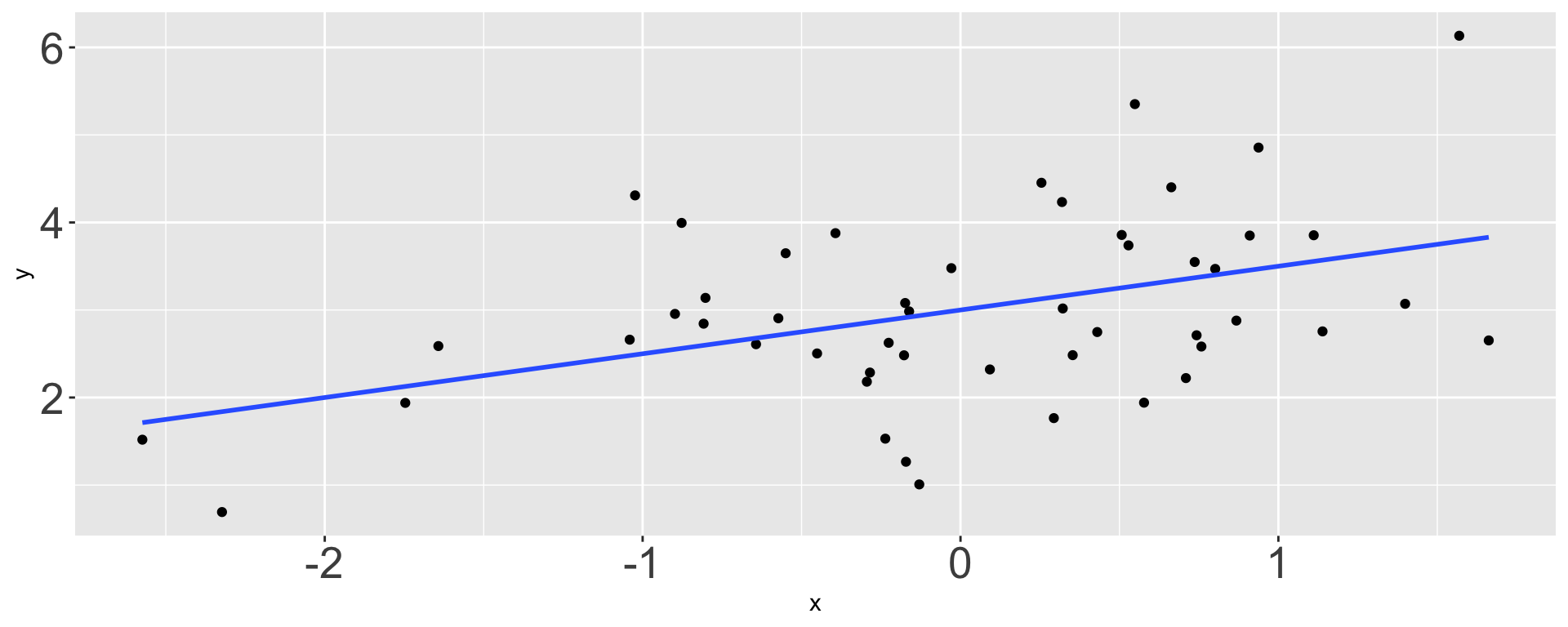
- 1
- 1.75
- 2
- 3
Which is a 98% confidence interval?
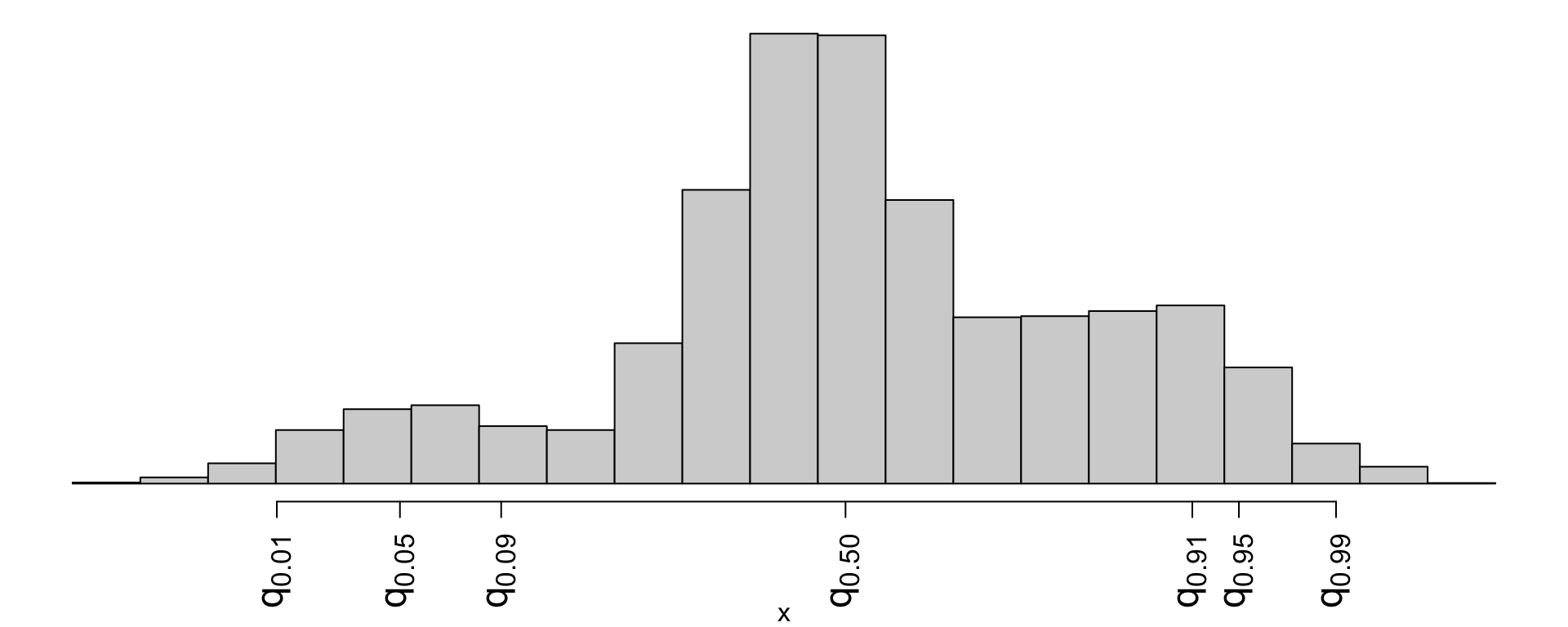
- \((q_{0.01},\,q_{0.91})\)
- \((q_{0.01},\,q_{0.99})\)
- \((q_{0.09},\,q_{0.95})\)
- \((q_{0.05},\,q_{0.99})\)
Match the picture to the p-value.
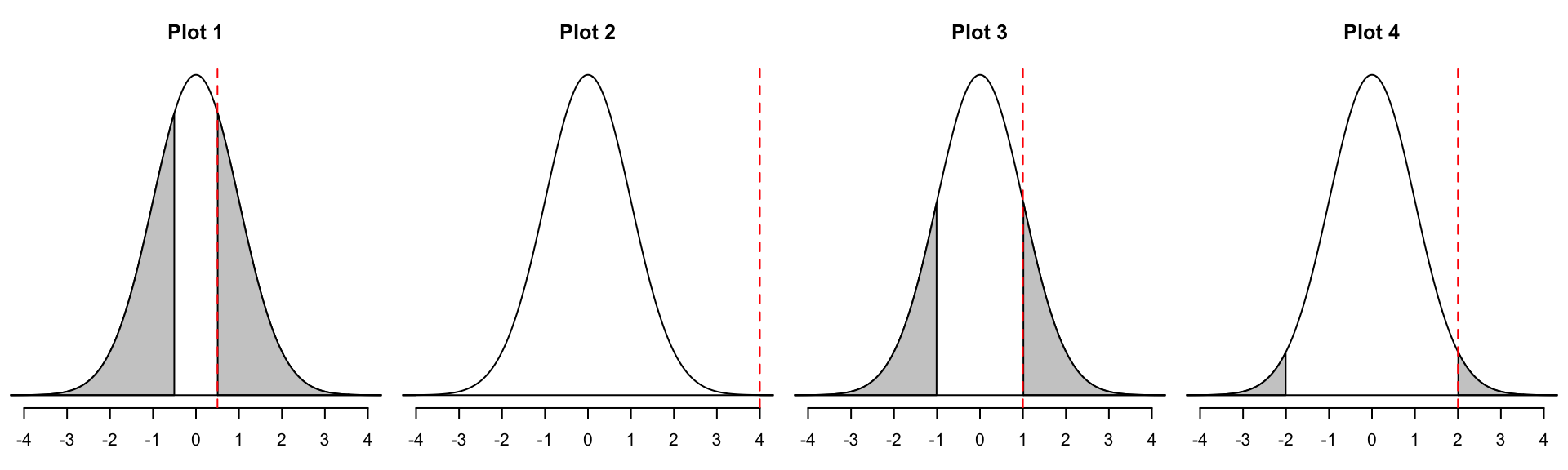
- 0
- 0.045
- 0.32
- 0.62
Which could be the null distribution of the test?
For these hypotheses
\[ \begin{aligned} H_0&: \beta_1=5\\ H_A&: \beta_1\neq 5. \end{aligned} \]