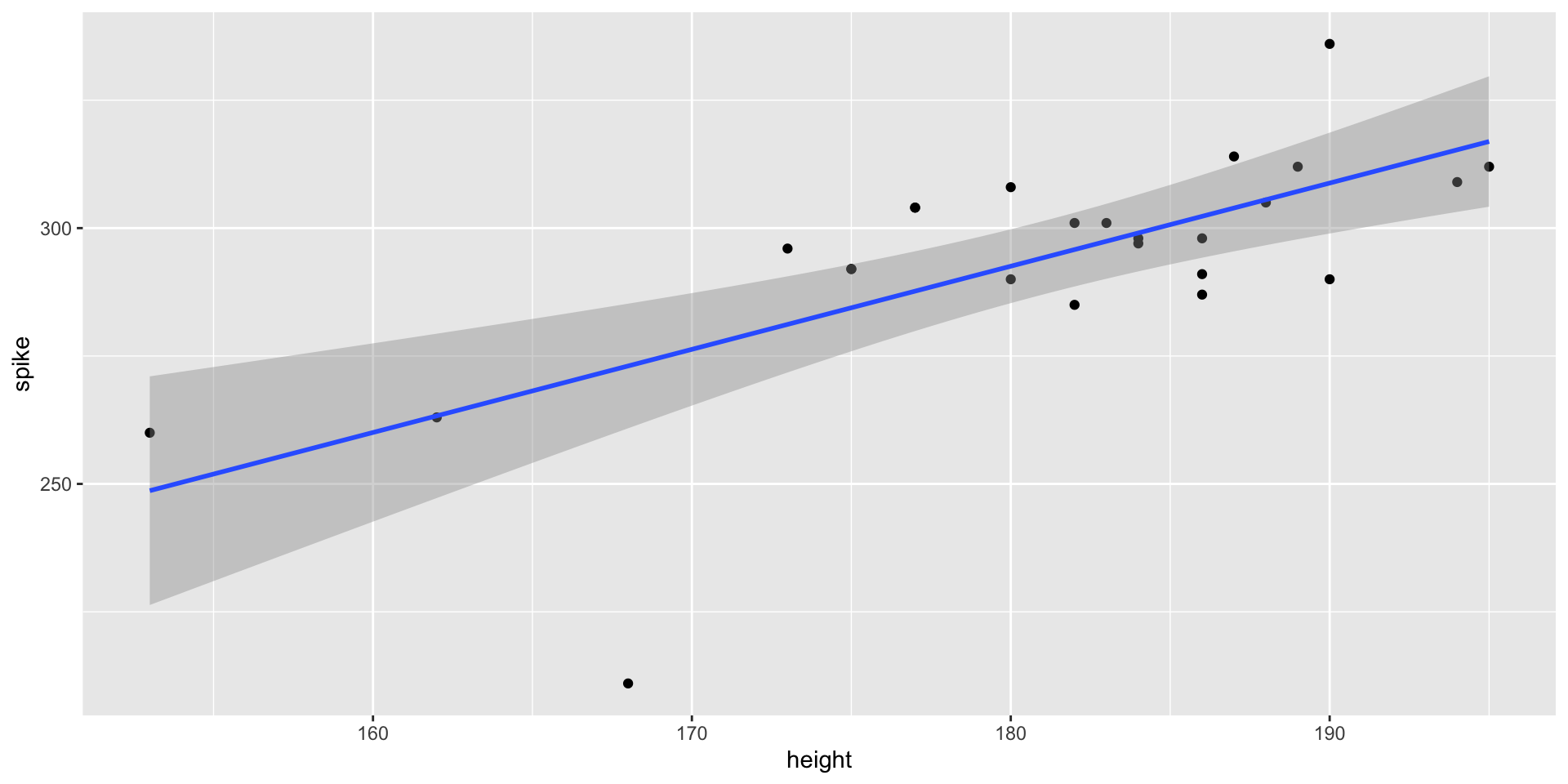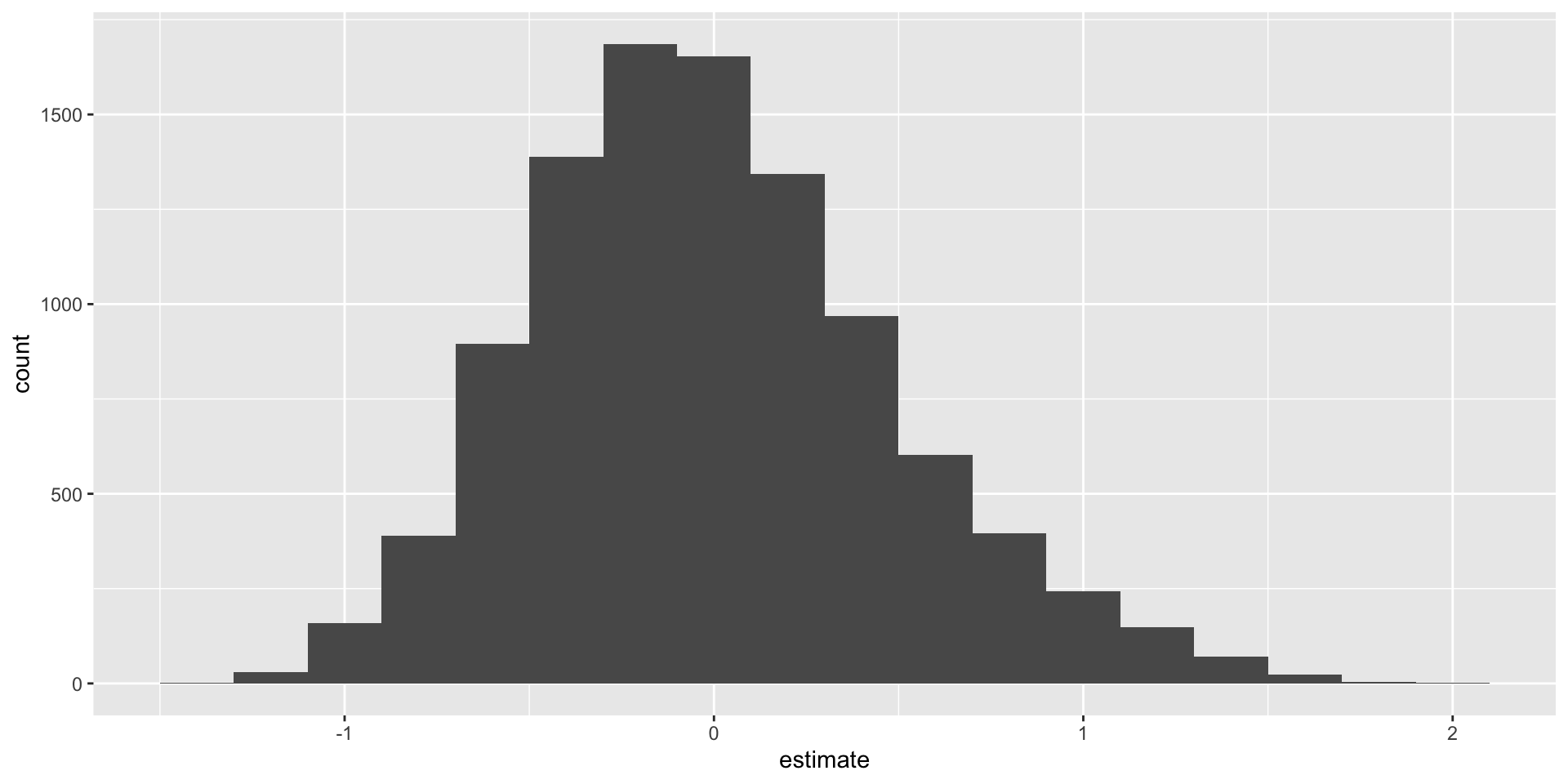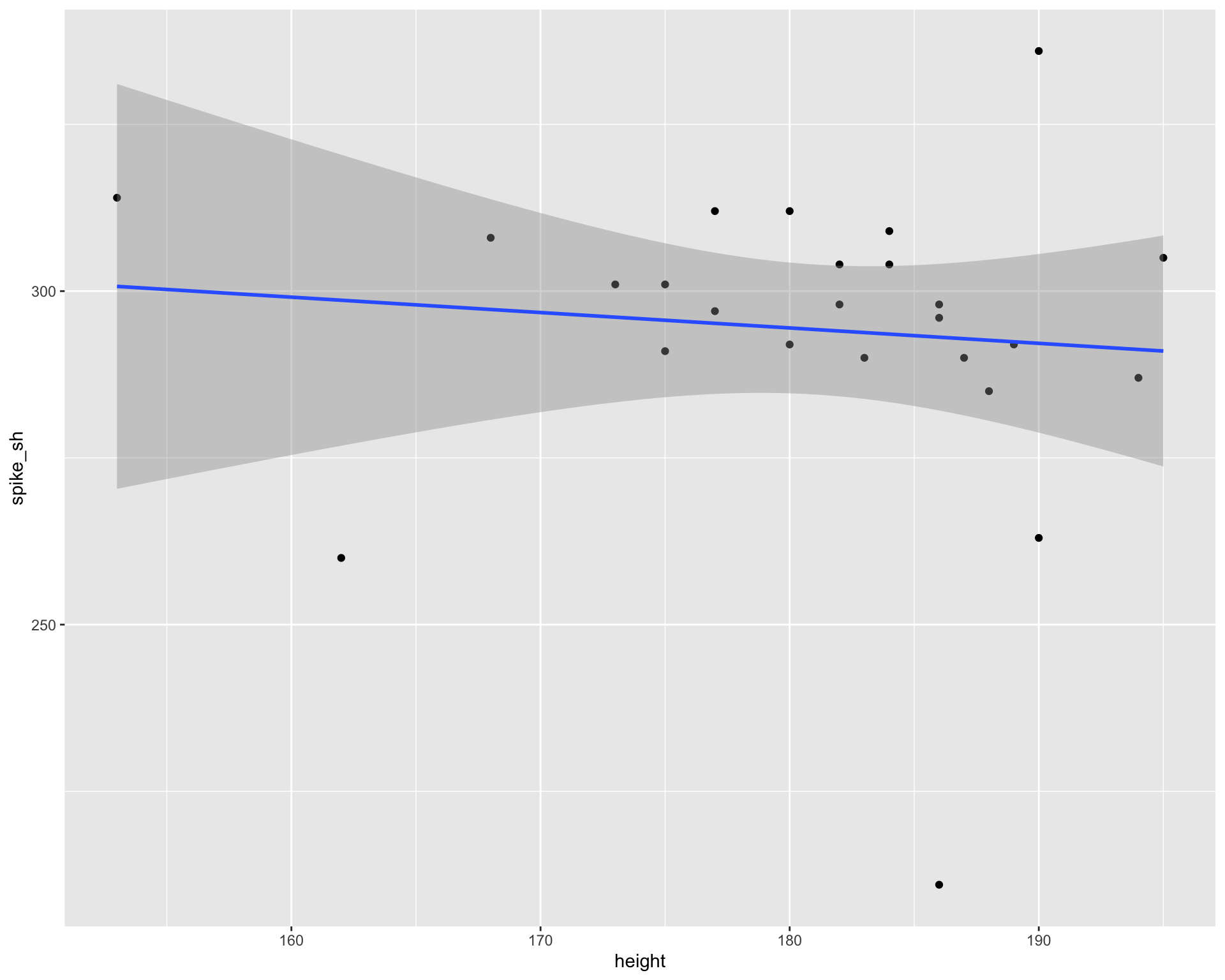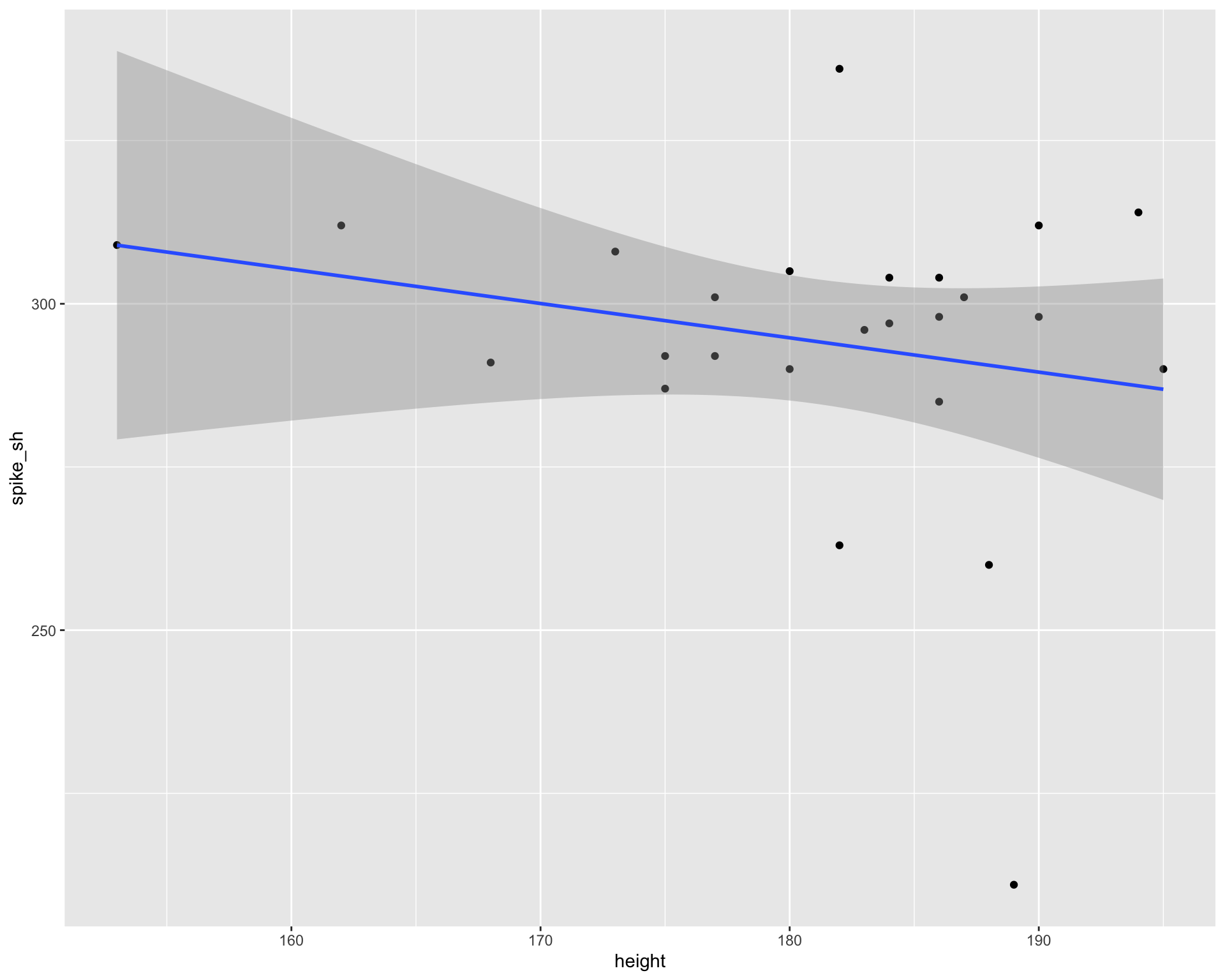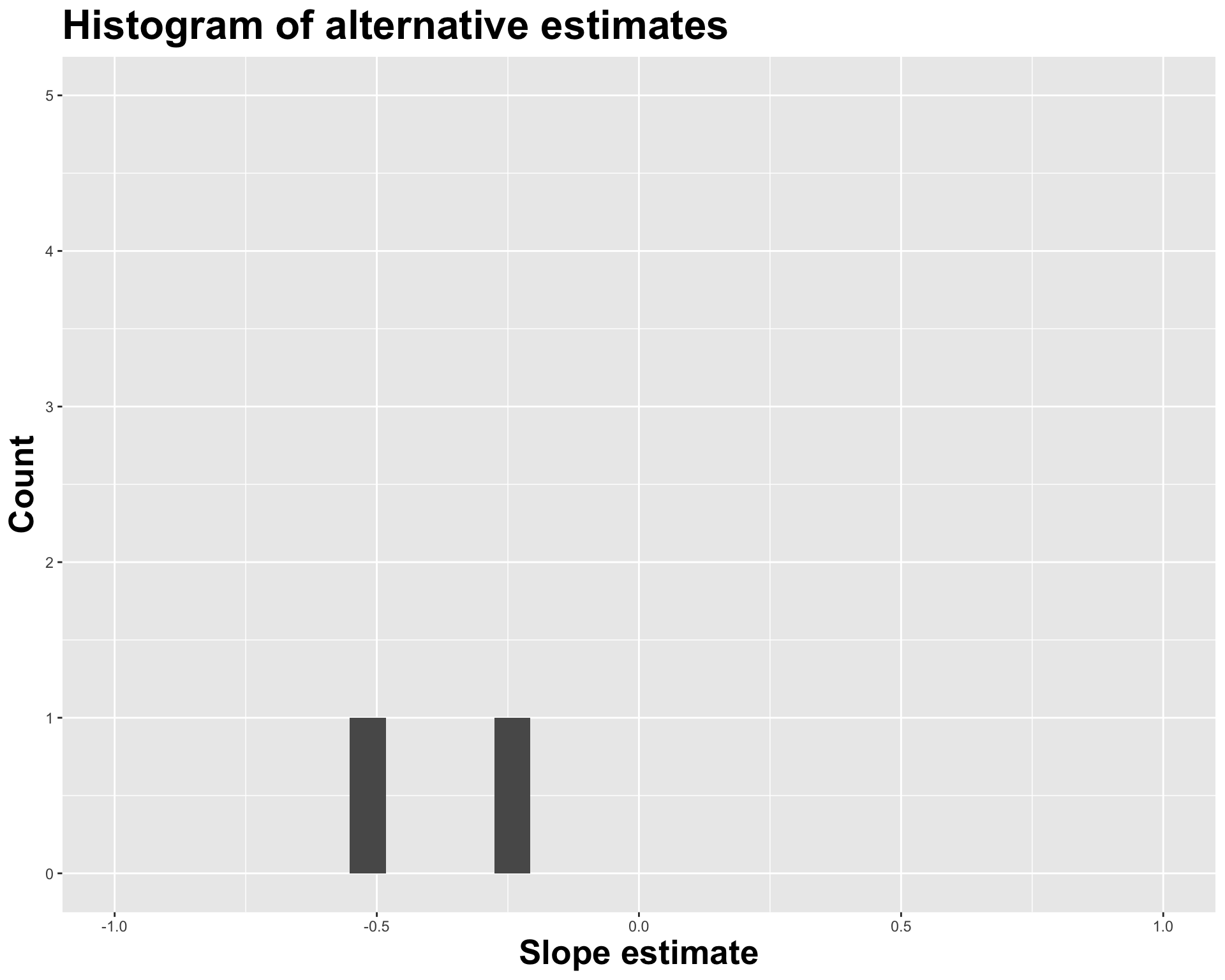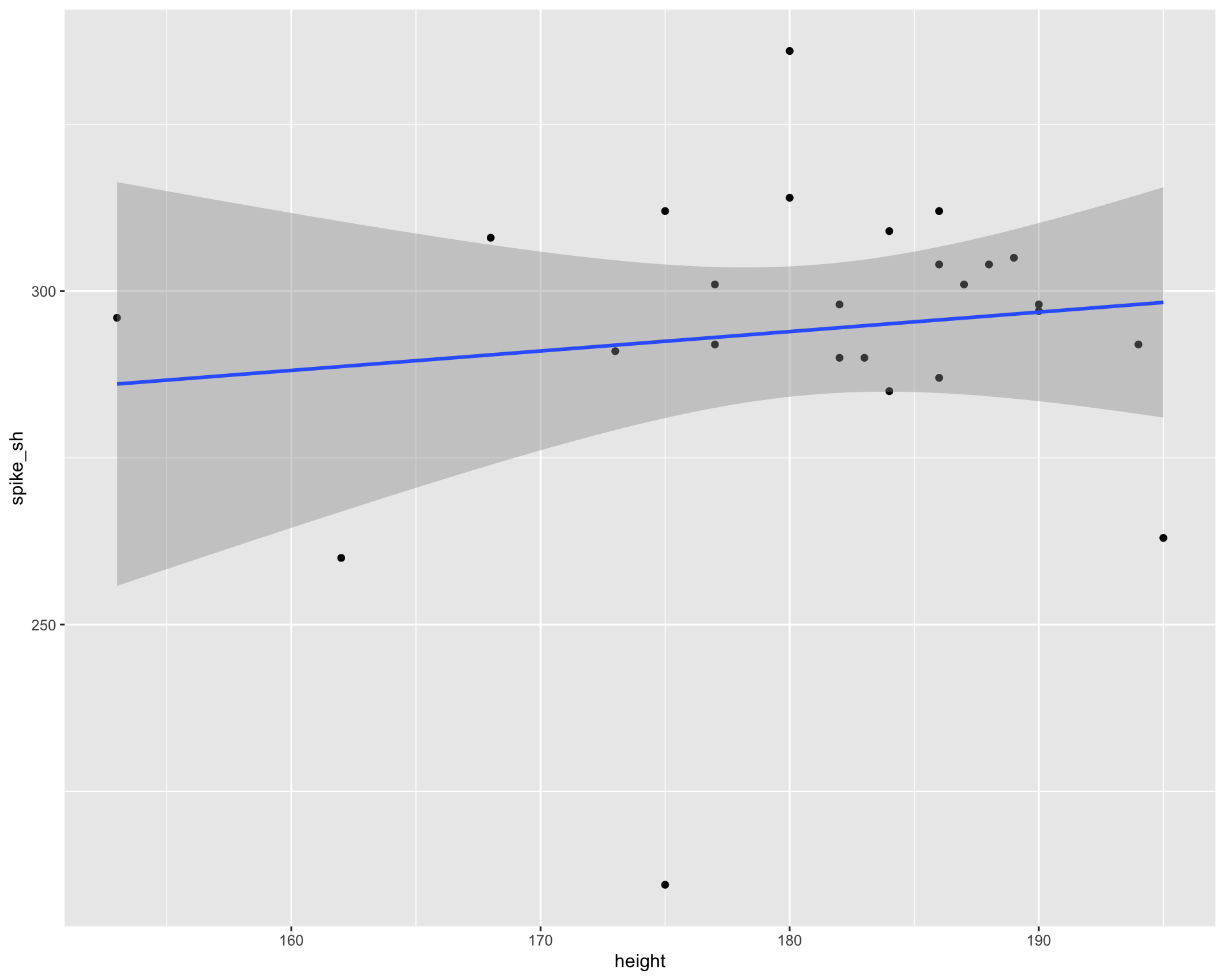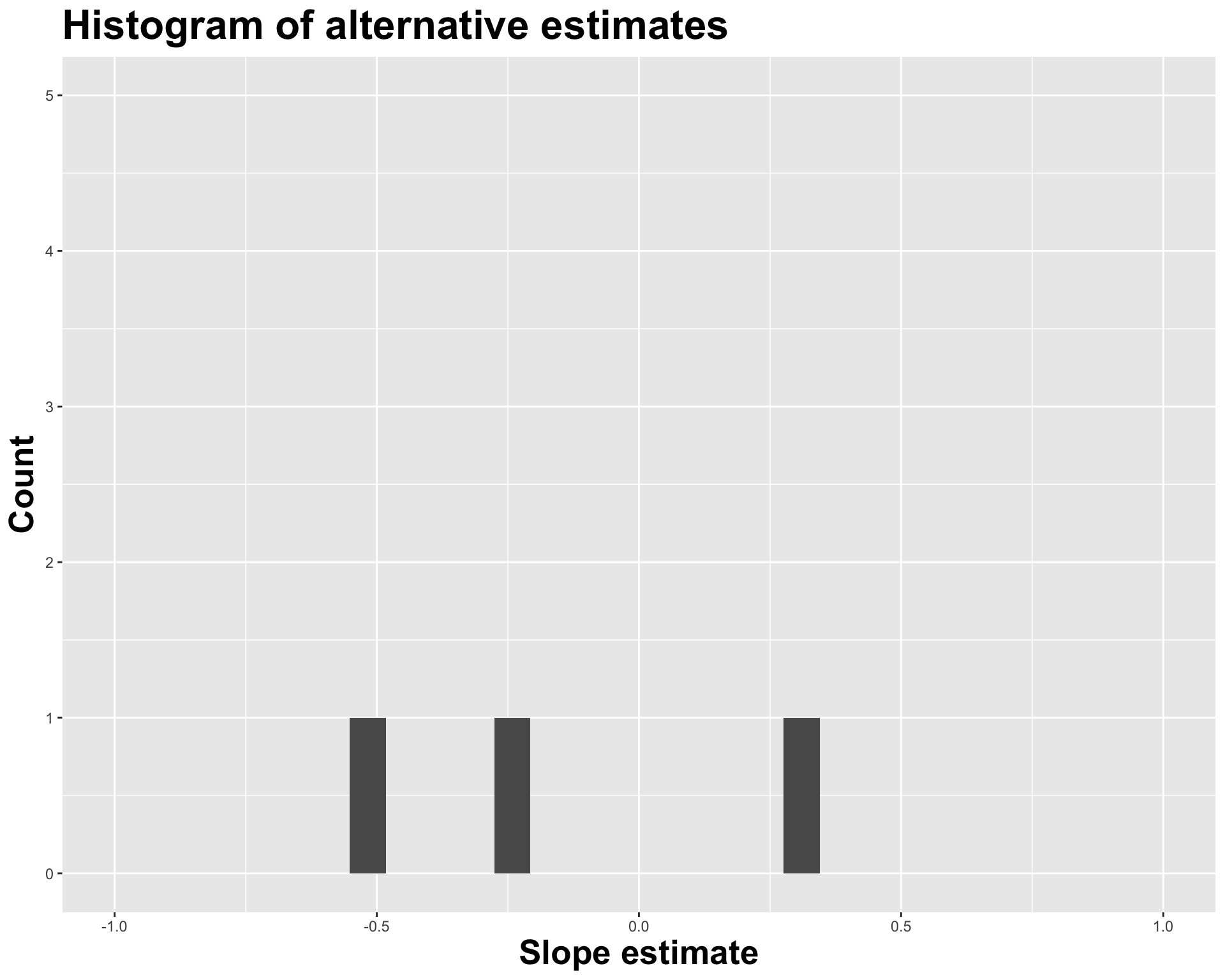
glimpse(volleyball)Rows: 25
Columns: 4
$ name <chr> "Maguilaura Frias", "Maria Elena Aguilera", "Mitzy Natalia Gonz…
$ height <dbl> 186, 153, 168, 173, 162, 190, 180, 184, 188, 195, 186, 175, 183…
$ spike <dbl> 291, 260, 211, 296, 263, 290, 308, 298, 305, 312, 298, 292, 301…
$ block <dbl> 280, 240, 209, 286, 253, 285, 231, 295, 295, 300, 285, 281, 288…