Midterm 2 Study Guide
Note
Answers are here.
Midterm Exam 2 focuses on the modeling material that has been introduced since spring break. As such, you should be spending most of your time with these:
- Lecture 15 (intro to models)
- Lecture 16 (simple linear regression)
- Lecture 17 (multiple linear regression)
- Lecture 18 (multiple linear regression)
- Lecture 19 (logistic regression)
- Lecture 20 (logistic regression)
- Lecture 21 (logistic regression)
- Lab 6
- Lab 7
- HW 5
- HW 6
The exam consists of two parts:
- In-class portion
- Wednesday April 8 at 11:45 AM - 1:00 PM in Griffith Theater;
- Worth 80% of your Midterm 2 grade;
- All multiple choice;
- Your only resource is both sides of one 8.5” x 11” note sheet that you and only you created (written, typed, iPad, etc);
- Take-home portion
- Released Thursday April 9 at 6:00 PM;
- Due Sunday April 12 at 11:59 PM;
- Worth 20% of your Midterm 2 grade;
- Similar to a homework assignment, but shorter;
- Completely open resource (open note, open internet, open ChatGPT, open everything), but citation policies apply, and collaboration between students is forbidden.
Here is our advice about how you should prioritize your studying. Below are 35 practice questions to get your wheels spinning.
Try this
Attempt all of the problems below without resources. Make note of your pain points and blind spots along the way. That might give you an idea of the stuff you would benefit from if you had it on a cheat sheet.
Concepts and main ideas
Question 1
Can you answer each of these in one or two sentences?
- When we plot a line of best fit for a numerical predictor and numerical response, what does “best” mean?
- What does the correlation coefficient between two numerical variables measure?
- What does the \(R^2\) of a linear regression measure?
- What is the main lesson of examples like Anscombe’s Quartet or the datasauRus dozen?
- What is the difference between \(Y=\beta_0+\beta_1 X + \varepsilon\) and \(\hat{Y}=b_0+b_1 X\)?
- Under what circumstances is the intercept in a regression model a meaningful quantity?
- If you run a “simple” linear regression model with a numerical response and a categorical predictor with three levels, what does the computer actually do to estimate that model?
- Consider this bit of toy code:
linear_reg() |> fit(_BLANK_, df)? What goes in the blank? What purpose does that argument serve, and how do you use it? - Let \(\hat{y}^{(\text{old})}\) be the prediction at \(x\) of a simple linear regression, and let \(\hat{y}^{(\text{new})}\) be the prediction at \(x+1\) of the same regression. How are \(\hat{y}^{(\text{old})}\) and \(\hat{y}^{(\text{new})}\) related? In other words, how does the prediction of the simple linear regression model change when you change the input from \(x\) to \(x+1\)?
- Let \(\hat{o}^{(\text{old})}\) be the estimated odds at \(x\) from a simple logistic regression model, and let \(\hat{o}^{(\text{new})}\) be the estimated odds at \(x+1\) of the same regression. How are \(\hat{o}^{(\text{old})}\) and \(\hat{o}^{(\text{new})}\) related? In other words, how does the prediction of the simple logistic regression model change when you change the input from \(x\) to \(x+1\)?
- Why is adjusted \(R^2\) a better model selection criterion than unadjusted \(R^2\)?
Visual understanding
Question 2
Practice!
https://www.rossmanchance.com/applets/2021/guesscorrelation/GuessCorrelation.html
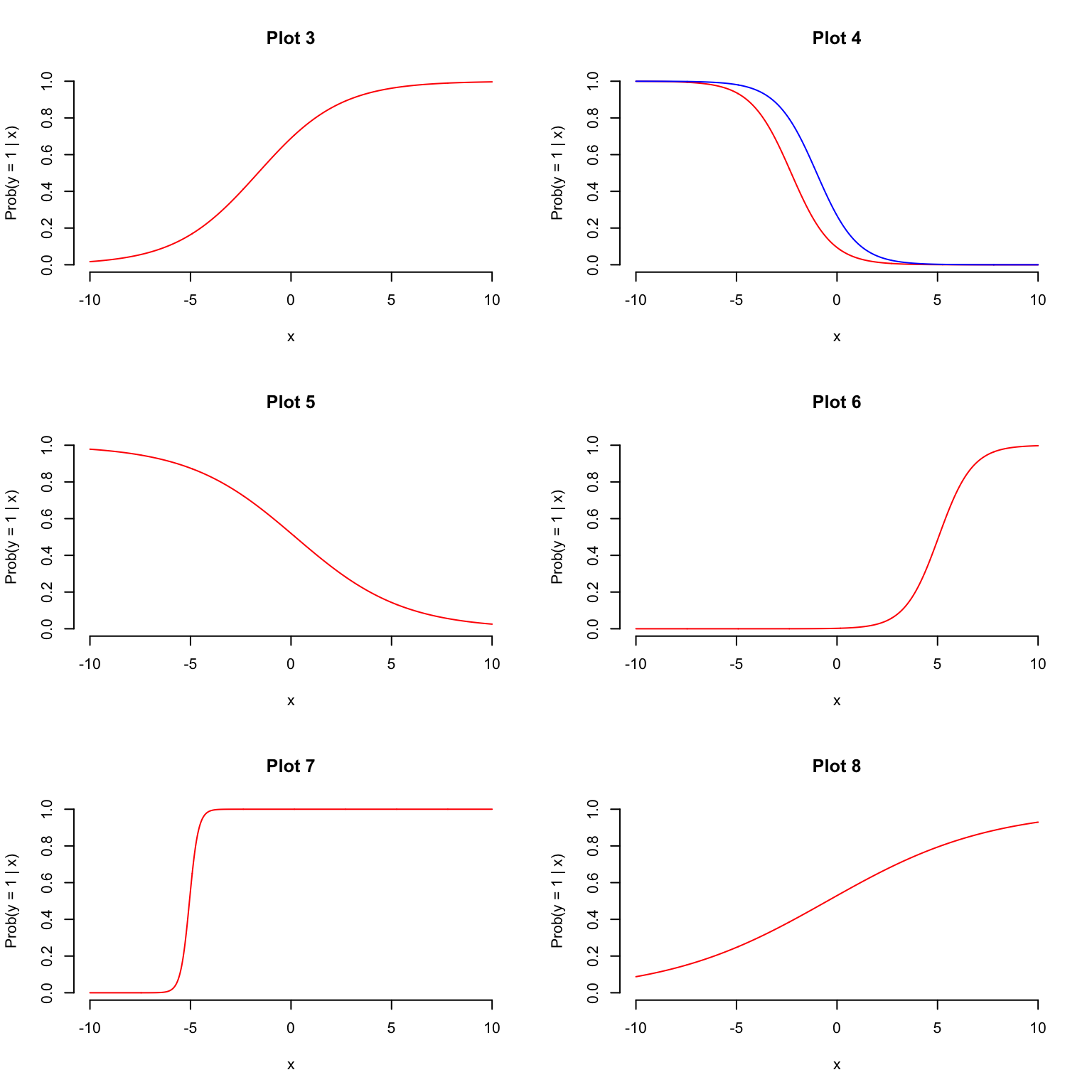
Questions 3 - 8
In what follows, let \(y\) be a binary response, let \(x\) be a numerical predictor, and let \(z\) be a binary predictor. Match the S-curve to the model equation.
- \(\log\left(\frac{\hat{p}}{1-\hat{p}}\right) = 22.9 + 4.54 \times x\)
- \(\log\left(\frac{\hat{p}}{1-\hat{p}}\right) = 0.118 + 0.246 \times x\)
- \(\log\left(\frac{\hat{p}}{1-\hat{p}}\right) = 0.798 + 0.486 \times x\)
- \(\log\left(\frac{\hat{p}}{1-\hat{p}}\right) = -6.035 + 1.194 \times x\)
- \(\log\left(\frac{\hat{p}}{1-\hat{p}}\right) = -2.26 - 0.99 \times x+1.26\times z\)
- \(\log\left(\frac{\hat{p}}{1-\hat{p}}\right) = 0.079 -0.373 \times x\)
Questions 9 - 12
Recall the dataset on spam emails:
email# A tibble: 3,921 × 21
spam exclaim_mess to_multiple from cc sent_email time
<fct> <dbl> <fct> <fct> <int> <fct> <dttm>
1 0 0 0 1 0 0 2012-01-01 01:16:41
2 0 1 0 1 0 0 2012-01-01 02:03:59
3 0 6 0 1 0 0 2012-01-01 11:00:32
4 0 48 0 1 0 0 2012-01-01 04:09:49
5 0 1 0 1 0 0 2012-01-01 05:00:01
6 0 1 0 1 0 0 2012-01-01 05:04:46
7 0 1 1 1 0 1 2012-01-01 12:55:06
8 0 18 1 1 1 1 2012-01-01 13:45:21
9 0 1 0 1 0 0 2012-01-01 16:08:59
10 0 0 0 1 0 0 2012-01-01 13:12:00
# ℹ 3,911 more rows
# ℹ 14 more variables: image <dbl>, attach <dbl>, dollar <dbl>, winner <fct>,
# inherit <dbl>, viagra <dbl>, password <dbl>, num_char <dbl>,
# line_breaks <int>, format <fct>, re_subj <fct>, exclaim_subj <dbl>,
# urgent_subj <fct>, number <fct>Here is a regression model trained on all of these data:
log_fit <- logistic_reg() |>
fit(spam ~ ., data = email)The in-sample predictions of the model are here:
email_aug <- augment(log_fit, email)
email_aug# A tibble: 3,921 × 24
.pred_class .pred_0 .pred_1 spam exclaim_mess to_multiple from cc
<fct> <dbl> <dbl> <fct> <dbl> <fct> <fct> <int>
1 0 0.867 1.33e- 1 0 0 0 1 0
2 0 0.943 5.70e- 2 0 1 0 1 0
3 0 0.942 5.78e- 2 0 6 0 1 0
4 0 0.920 7.96e- 2 0 48 0 1 0
5 0 0.903 9.74e- 2 0 1 0 1 0
6 0 0.901 9.87e- 2 0 1 0 1 0
7 0 1.000 7.89e-12 0 1 1 1 0
8 0 1.000 1.24e-12 0 18 1 1 1
9 0 0.862 1.38e- 1 0 1 0 1 0
10 0 0.922 7.76e- 2 0 0 0 1 0
# ℹ 3,911 more rows
# ℹ 16 more variables: sent_email <fct>, time <dttm>, image <dbl>,
# attach <dbl>, dollar <dbl>, winner <fct>, inherit <dbl>, viagra <dbl>,
# password <dbl>, num_char <dbl>, line_breaks <int>, format <fct>,
# re_subj <fct>, exclaim_subj <dbl>, urgent_subj <fct>, number <fct>To see how well the model did, we can compute the classification error rates for different thresholds and summarize the results with the ROC curve:
email_roc <- roc_curve(email_aug, truth = spam, .pred_1, event_level = "second")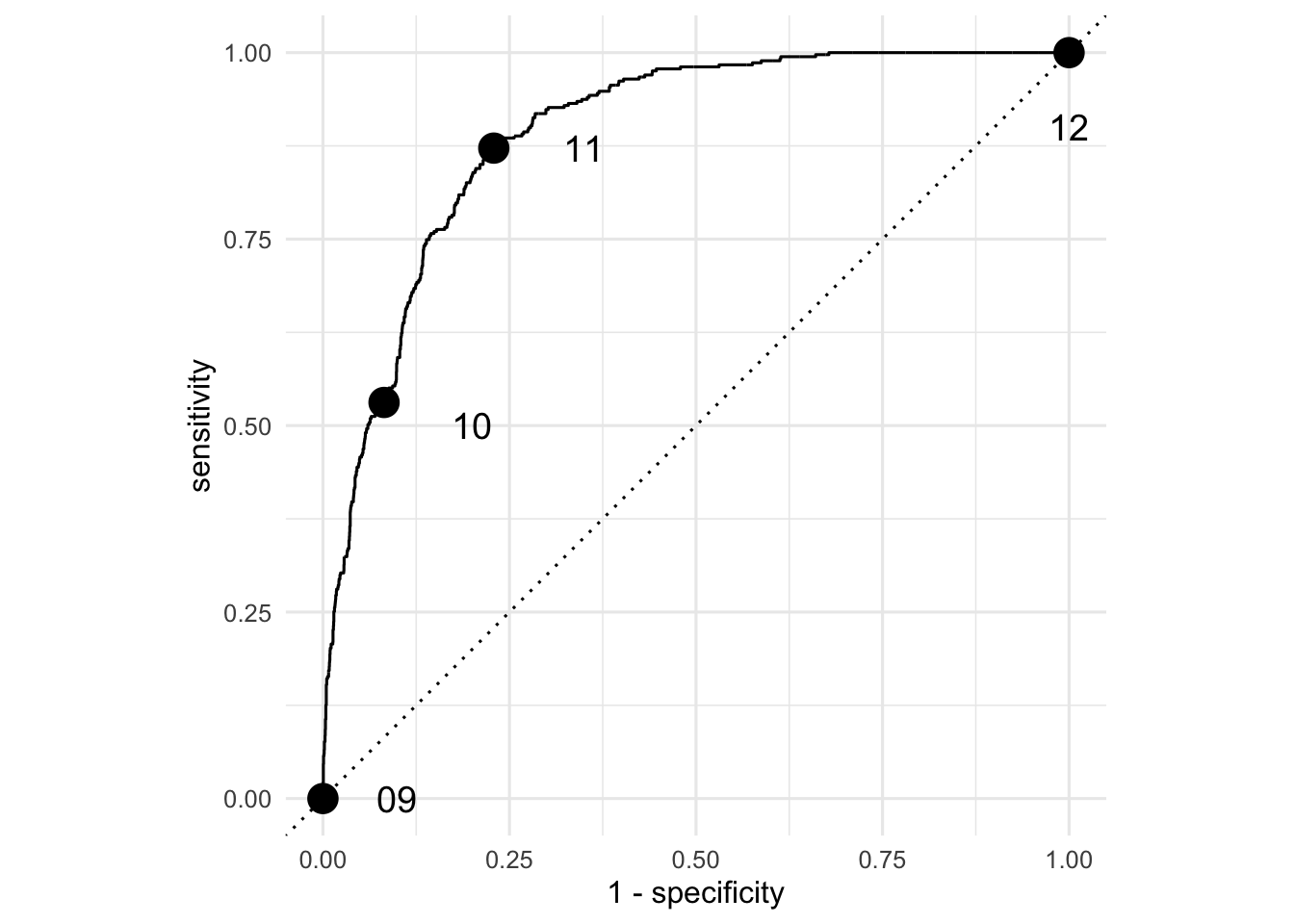
Match the point on the ROC curve to the threshold that was used to compute it.
email_aug |>
mutate(.pred_class = if_else(.pred_1 <= 0.25, 0, 1)) |>
count(spam, .pred_class) |> group_by(spam) |> mutate(prop = n / sum(n))# A tibble: 4 × 4
# Groups: spam [2]
spam .pred_class n prop
<fct> <dbl> <int> <dbl>
1 0 0 3263 0.918
2 0 1 291 0.0819
3 1 0 172 0.469
4 1 1 195 0.531 email_aug |>
mutate(.pred_class = if_else(.pred_1 <= 0.0, 0, 1)) |>
count(spam, .pred_class) |> group_by(spam) |> mutate(prop = n / sum(n))# A tibble: 2 × 4
# Groups: spam [2]
spam .pred_class n prop
<fct> <dbl> <int> <dbl>
1 0 1 3554 1
2 1 1 367 1email_aug |>
mutate(.pred_class = if_else(.pred_1 <= 1.00, 0, 1)) |>
count(spam, .pred_class) |> group_by(spam) |> mutate(prop = n / sum(n))# A tibble: 2 × 4
# Groups: spam [2]
spam .pred_class n prop
<fct> <dbl> <int> <dbl>
1 0 0 3554 1
2 1 0 367 1email_aug |>
mutate(.pred_class = if_else(.pred_1 <= 0.1, 0, 1)) |>
count(spam, .pred_class) |> group_by(spam) |> mutate(prop = n / sum(n))# A tibble: 4 × 4
# Groups: spam [2]
spam .pred_class n prop
<fct> <dbl> <int> <dbl>
1 0 0 2740 0.771
2 0 1 814 0.229
3 1 0 47 0.128
4 1 1 320 0.872WANANA doctor
What’s wrong with the interpretations below? Diagnose the problem and fix it if possible.
Question 13
Some bozo ran this regression and wrote the following interpretation:
linear_reg() |>
fit(bill_length_mm ~ flipper_length_mm, penguins) |>
tidy()# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -7.26 3.20 -2.27 2.38e- 2
2 flipper_length_mm 0.255 0.0159 16.0 1.74e-43If the flipper length of a penguin increases by 1mm, then the bill length will increase by 0.25mm.
Question 14
Some schmuck ran this regression and wrote the following interpretation:
logistic_reg() |>
fit(spam ~ num_char, email) |>
tidy()# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -1.80 0.0716 -25.1 2.04e-139
2 num_char -0.0621 0.00801 -7.75 9.50e- 15If the number of characters in an email increases by 1000, then the estimated probability of that email being spam is lower by -0.062, on average.
FYI: from the documentation (?email), num_char is “The number of characters in the email, in thousands.”
Question 15
Some putz ran this regression and wrote the following interpretation:
linear_reg() |>
fit(body_mass_g ~ flipper_length_mm + bill_length_mm, penguins) |>
tidy()# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -5737. 308. -18.6 7.80e-54
2 flipper_length_mm 48.1 2.01 23.9 7.56e-75
3 bill_length_mm 6.05 5.18 1.17 2.44e- 1If flipper length and bill length both increase by 1mm, then we predict that body mass is lower by 48.14 grams, on average.
Question 16
Some blockhead ran this regression and wrote the following interpretation:
linear_reg() |>
fit(body_mass_g ~ flipper_length_mm * species, penguins) |>
tidy()# A tibble: 6 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -2536. 879. -2.88 4.19e- 3
2 flipper_length_mm 32.8 4.63 7.10 7.69e-12
3 speciesChinstrap -501. 1523. -0.329 7.42e- 1
4 speciesGentoo -4251. 1427. -2.98 3.11e- 3
5 flipper_length_mm:speciesChinstrap 1.74 7.86 0.222 8.25e- 1
6 flipper_length_mm:speciesGentoo 21.8 6.94 3.14 1.84e- 3If the flipper length of a Chinstrap penguin increases by 1mm, then we predict that the body mass is higher by 1.74 grams on average.
Question 17
Some nitwit ran this regression and wrote the following interpretation:
linear_reg() |>
fit(hp ~ mpg, mtcars) |>
glance()# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.602 0.589 43.9 45.5 0.000000179 1 -165. 337. 341.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>About 60% of the observed variation in miles/gallon is explained by the model.
Question 18
Some chooch ran this regression and wrote the following interpretation:
logistic_reg() |>
fit(spam ~ exclaim_mess + viagra + dollar, email) |>
tidy()# A tibble: 4 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -2.22 0.0568 -39.1 0
2 exclaim_mess 0.00189 0.00108 1.75 0.0794
3 viagra 1.86 40.6 0.0459 0.963
4 dollar -0.0656 0.0208 -3.15 0.00165If an email contains no exclamation marks, no dollar signs, and no mentions of viagra, then the model predicts that the probability of it being spam is \(e^{-2.218}\approx 0.10886\).
Question 19
Some nincompoop ran this regression and wrote the following interpretation:
linear_reg() |>
fit(bill_length_mm ~ bill_depth_mm + sex, penguins) |>
tidy()# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 61.0 2.35 26.0 7.39e-82
2 bill_depth_mm -1.15 0.141 -8.16 7.35e-15
3 sexmale 5.44 0.555 9.81 4.18e-20If a male penguin has a bill depth of 0mm (sad!), then we expect its bill length to be 60.99mm on average.
Question 20
Some silly goose ran this regression and wrote the following interpretation:
linear_reg() |>
fit(body_mass_g ~ flipper_length_mm + bill_length_mm, penguins) |>
glance()# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.760 0.759 394. 537. 9.09e-106 2 -2528. 5063. 5079.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>The correlation between body mass, flipper length, and bill length is about \(\sqrt{0.76}\approx 0.87\).
Data analysis
Blizzard salaries
In 2020, employees of Blizzard Entertainment circulated a spreadsheet to anonymously share salaries and recent pay increases amidst rising tension in the video game industry over wage disparities and executive compensation. (Source: Blizzard Workers Share Salaries in Revolt Over Pay)
The name of the data frame used for this analysis is blizzard_salary and the variables are:
percent_incr: Raise given in July 2020, as percent increase with values ranging from 1 (1% increase) to 21.5 (21.5% increase)salary_type: Type of salary, with levelsHourlyandSalariedannual_salary: Annual salary, in USD, with values ranging from $50,939 to $216,856.performance_rating: Most recent review performance rating, with levelsPoor,Successful,High, andTop. ThePoorlevel is the lowest rating and theToplevel is the highest rating.
The first ten rows of blizzard_salary are shown below:
# A tibble: 409 × 4
percent_incr salary_type annual_salary performance_rating
<dbl> <chr> <dbl> <chr>
1 1 Salaried 1 High
2 1 Salaried 1 Successful
3 1 Salaried 1 High
4 1 Hourly 33987. Successful
5 NA Hourly 34798. High
6 NA Hourly 35360 <NA>
7 NA Hourly 37440 <NA>
8 0 Hourly 37814. <NA>
9 4 Hourly 41101. Top
10 1.2 Hourly 42328 <NA>
# ℹ 399 more rowsQuestion 21
You fit a model for predicting raises (percent_incr) from salaries (annual_salary). We’ll call this model raise_1_fit. A tidy output of the model is shown below.
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 1.87 0.432 4.33 0.0000194
2 annual_salary 0.0000155 0.00000452 3.43 0.000669 Which of the following is the best interpretation of the slope coefficient?
- For every additional $1,000 of annual salary, the model predicts the raise to be higher, on average, by 1.55%.
- For every additional $1,000 of annual salary, the raise goes up by 0.0155%.
- For every additional $1,000 of annual salary, the model predicts the raise to be higher, on average, by 0.0155%.
- For every additional $1,000 of annual salary, the model predicts the raise to be higher, on average, by 1.87%.
Question 22
You then fit a model for predicting raises (percent_incr) from salaries (annual_salary) and performance ratings (performance_rating). We’ll call this model raise_2_fit. Which of the following is definitely true based on the information you have so far?
- Intercept of
raise_2_fitis higher than intercept ofraise_1_fit. - Slope of
raise_2_fitis higher than RMSE ofraise_1_fit. - Adjusted \(R^2\) of
raise_2_fitis higher than adjusted \(R^2\) ofraise_1_fit. -
\(R^2\) of
raise_2_fitis higher \(R^2\) ofraise_1_fit.
Question 23
The tidy model output for the raise_2_fit model you fit is shown below.
# A tibble: 5 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.55 0.508 6.99 1.99e-11
2 annual_salary 0.00000989 0.00000436 2.27 2.42e- 2
3 performance_ratingPoor -4.06 1.42 -2.86 4.58e- 3
4 performance_ratingSuccessful -2.40 0.397 -6.05 4.68e- 9
5 performance_ratingTop 2.99 0.715 4.18 3.92e- 5When your teammate sees this model output, they remark
“The coefficient for
performance_ratingSuccessfulis negative. That’s weird. I guess it means that people who get successful performance ratings get lower raises.”
How would you respond to your teammate?
Question 24
Ultimately, your teammate decides they don’t like the negative slope coefficients in the model output you created (not that there’s anything wrong with negative slope coefficients!), does something else, and comes up with the following model output.
# A tibble: 5 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -0.511 1.47 -0.347 0.729
2 annual_salary 0.00000989 0.00000436 2.27 0.0242
3 performance_ratingSuccessful 1.66 1.42 1.17 0.242
4 performance_ratingHigh 4.06 1.42 2.86 0.00458
5 performance_ratingTop 7.05 1.53 4.60 0.00000644Unfortunately they didn’t write their code in a Quarto document, instead just wrote some code in the Console and then lost track of their work. They remember using the fct_relevel() function and doing something like the following:
blizzard_salary <- blizzard_salary |>
mutate(performance_rating = fct_relevel(performance_rating, ___))What should they put in the blanks to get the same model output as above?
- “Poor”, “Successful”, “High”, “Top”
- “Successful”, “High”, “Top”
- “Top”, “High”, “Successful”, “Poor”
- Poor, Successful, High, Top
Question 25
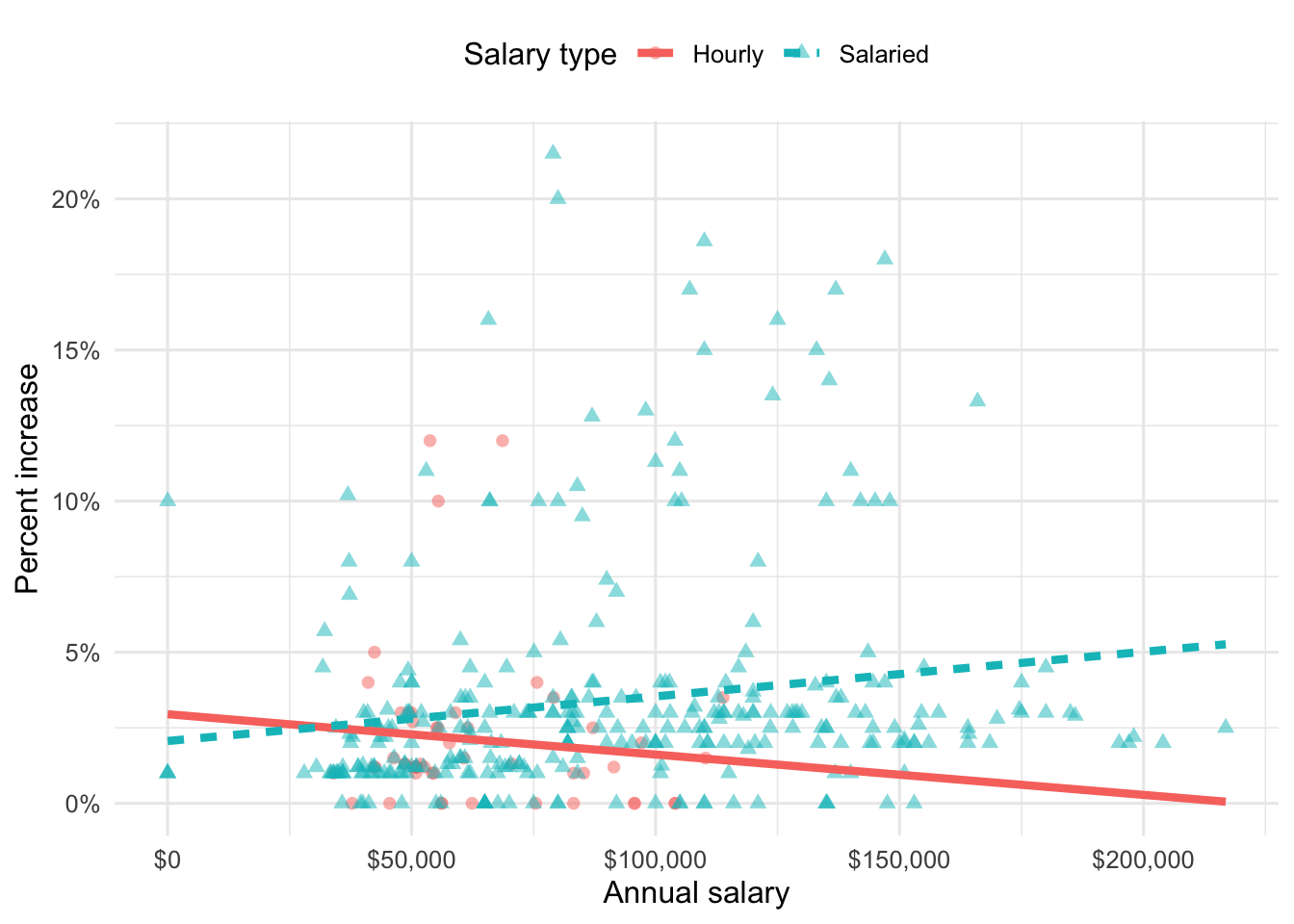
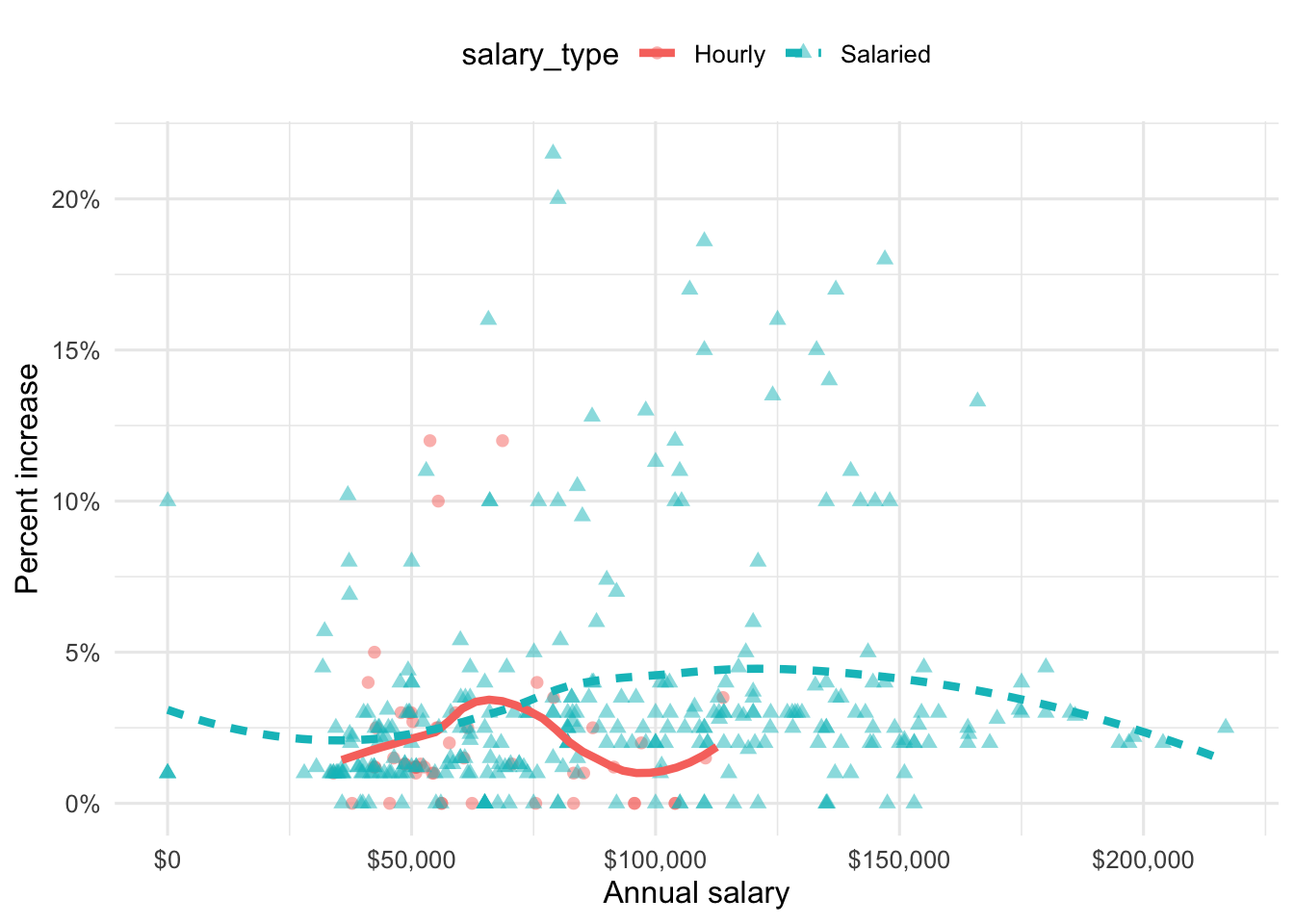
Suppose we fit a model to predict percent_incr from annual_salary and salary_type. A tidy output of the model is shown below.
# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 1.24 0.570 2.18 0.0300
2 annual_salary 0.0000137 0.00000464 2.96 0.00329
3 salary_typeSalaried 0.913 0.544 1.68 0.0938 Which of the following visualizations represent this model? Explain your reasoning.
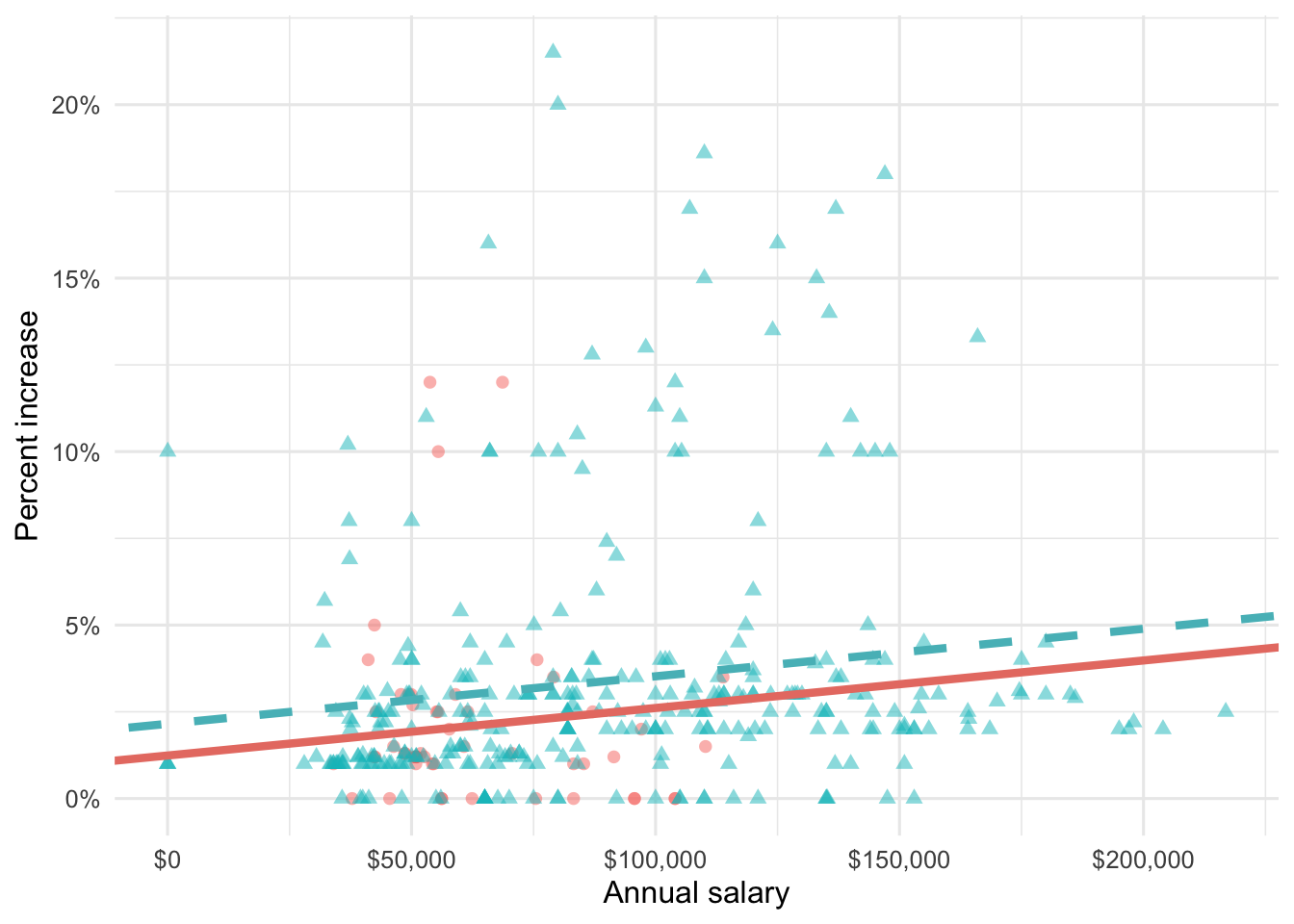
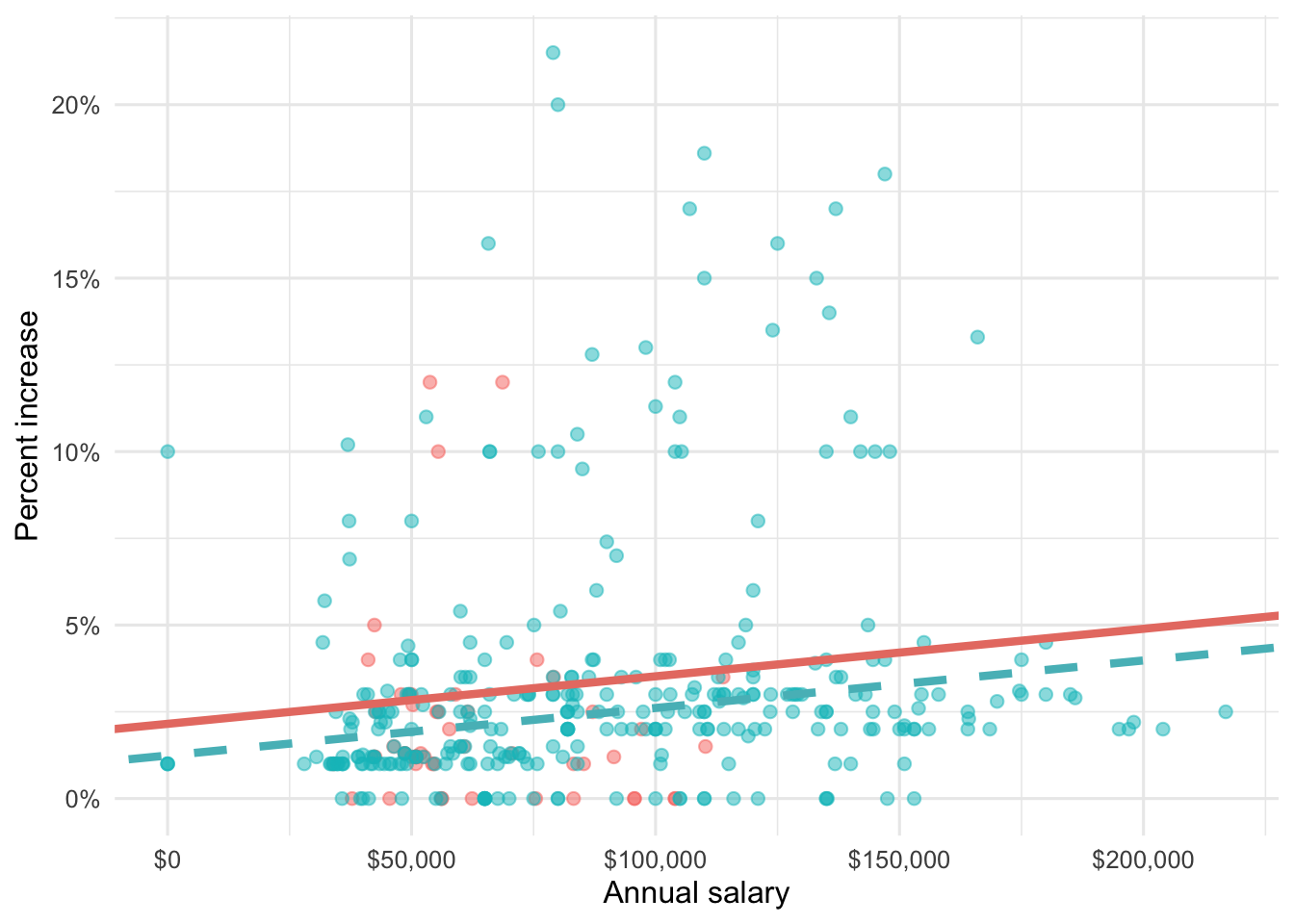
Question 26
Suppose you now fit a model to predict the natural log of percent increase, log(percent_incr), from performance rating. The model is called raise_4_fit.
You’re provided the following:
tidy(raise_4_fit) |>
select(term, estimate) |>
mutate(exp_estimate = exp(estimate))# A tibble: 4 × 3
term estimate exp_estimate
<chr> <dbl> <dbl>
1 (Intercept) -7.15 0.000786
2 performance_ratingSuccessful 6.93 1025.
3 performance_ratingHigh 8.17 3534.
4 performance_ratingTop 8.91 7438. Based on this, which of the following is true?
a. The model predicts that the percentage increase employees with Successful performance get, on average, is higher by 10.25% compared to the employees with Poor performance rating.
b. The model predicts that the percentage increase employees with Successful performance get, on average, is higher by 6.93% compared to the employees with Poor performance rating.
c. The model predicts that the percentage increase employees with Successful performance get, on average, is higher by a factor of 1025 compared to the employees with Poor performance rating.
d. The model predicts that the percentage increase employees with Successful performance get, on average, is higher by a factor of 6.93 compared to the employees with Poor performance rating.
Movies
The data for this part comes from the Internet Movie Database (IMDB). Specifically, the data are a random sample of movies released between 1980 and 2020.
The name of the data frame used for this analysis is movies, and it contains the variables shown in Table 1.
movies
| Variable | Description |
|---|---|
name |
name of the movie |
rating |
rating of the movie (R, PG, etc.) |
genre |
main genre of the movie. |
runtime |
duration of the movie |
year |
year of release |
release_date |
release date (YYYY-MM-DD) |
release_country |
release country |
score |
IMDB user rating |
votes |
number of user votes |
director |
the director |
writer |
writer of the movie |
star |
main actor/actress |
country |
country of origin |
budget |
the budget of a movie (some movies don’t have this, so it appears as 0) |
gross |
revenue of the movie |
company |
the production company |
The first thirty rows of the movies data frame are shown in Table 2, with variable types suppressed (since we’ll ask about them later).
First 30 rows of movies, with variable types suppressed.
# A tibble: 500 × 16
name score runtime genre rating release_country release_date
1 Blue City 4.4 83 mins Action R United States 1986-05-02
2 Winter Sleep 8.1 196 Drama Not Rated Turkey 2014-06-12
3 Rang De Basan… 8.1 167 Comedy Not Rated United States 2006-01-26
4 Pokémon Detec… 6.6 104 Action PG United States 2019-05-10
5 A Bad Moms Ch… 5.6 104 Comedy R United States 2017-11-01
6 Replicas 5.5 107 Drama PG-13 United States 2019-01-11
7 Windy City 5.8 103 Drama R Uruguay 1986-01-01
8 War for the P… 7.4 140 Action PG-13 United States 2017-07-14
9 Tales from th… 6.4 98 Crime R United States 1995-05-24
10 Fire with Fire 6.5 103 Drama PG-13 United States 1986-05-09
11 Raising Helen 6 119 Comedy PG-13 United States 2004-05-28
12 Feeling Minne… 5.4 99 Comedy R United States 1996-09-13
13 The Babe 5.9 115 Biography PG United States 1992-04-17
14 The Real Blon… 6 105 Comedy R United States 1998-02-27
15 To vlemma tou… 7.6 176 Drama Not Rated United States 1997-11-01
16 Going the Dis… 6.3 102 Comedy R United States 2010-09-03
17 Jung on zo 6.8 103 Action R Hong Kong 1993-06-24
18 Rita, Sue and… 6.5 93 Comedy R United Kingdom 1987-05-29
19 Phone Booth 7 81 Crime R United States 2003-04-04
20 Happy Death D… 6.6 96 Comedy PG-13 United States 2017-10-13
21 Barely Legal 4.7 90 Comedy R Thailand 2006-05-25
22 Three Kings 7.1 114 Action R United States 1999-10-01
23 Menace II Soc… 7.5 97 Crime R United States 1993-05-26
24 Four Rooms 6.8 98 Comedy R United States 1995-12-25
25 Quartet 6.8 98 Comedy PG-13 United States 2013-03-01
26 Tape 7.2 86 Drama R Denmark 2002-07-12
27 Marked for De… 6 93 Action R United States 1990-10-05
28 Congo 5.2 109 Action PG-13 United States 1995-06-09
29 Stop-Loss 6.4 112 Drama R United States 2008-03-28
30 Con Air 6.9 115 Action R United States 1997-06-06
# ℹ 470 more rows
# ℹ 9 more variables: budget, gross, votes, year,
# director, writer, star, company, countryScore vs. runtime
In this part, we fit a model predicting score from runtime and name it score_runtime_fit.
score_runtime_fit <- linear_reg() |>
fit(score ~ runtime, data = movies)Figure 2 visualizes the relationship between score and runtime as well as the linear model for predicting score from runtime. The first three movies in Table 2 are labeled in the visualization as well. Answer all questions in this part based on Figure 2.
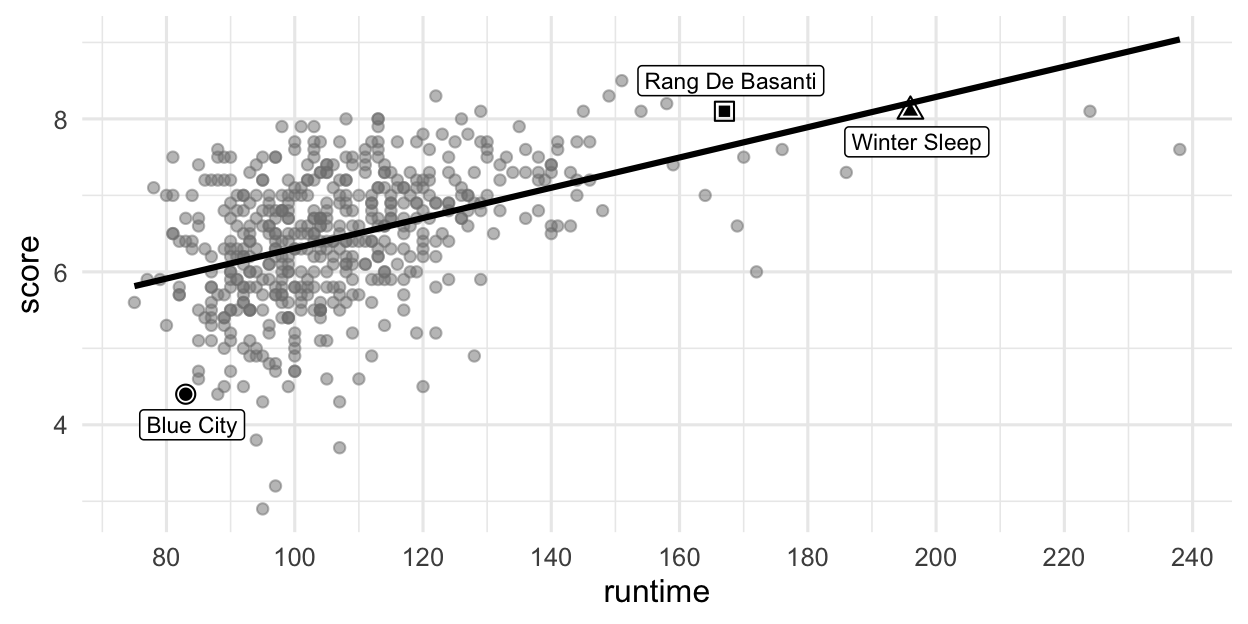
score vs. runtime for movies.
Question 27
Partial code for producing Figure 2 is given below. Which of the following goes in the blank on Line 2? Select all that apply.
grepl(" mins", runtime)grep(" mins", runtime)str_remove(runtime, " mins")as.numeric(str_remove(runtime, " mins"))na.rm(runtime)
Question 28
Based on this model, order the three labeled movies in Figure 2 in decreasing order of the magnitude (absolute value) of their residuals.
Winter Sleep > Rang De Basanti > Blue City
Winter Sleep > Blue City > Rang De Basanti
Rang De Basanti > Winter Sleep > Blue City
Blue City > Winter Sleep > Rang De Basanti
Blue City > Rang De Basanti > Winter Sleep
Question 29
The R-squared for the model visualized in Figure 2 is 31%. Which of the following is the best interpretation of this value?
31% of the variability in movie runtimes is explained by their scores.
31% of the variability in movie scores is explained by their runtime.
The model accurately predicts scores of 31% of the movies in this sample.
The model accurately predicts scores of 31% of all movies.
The correlation between scores and runtimes of movies is 0.31.
Score vs. runtime or year
The visualizations below show the relationship between score and runtime as well as score and year, respectively. Additionally, the lines of best fit are overlaid on the visualizations.
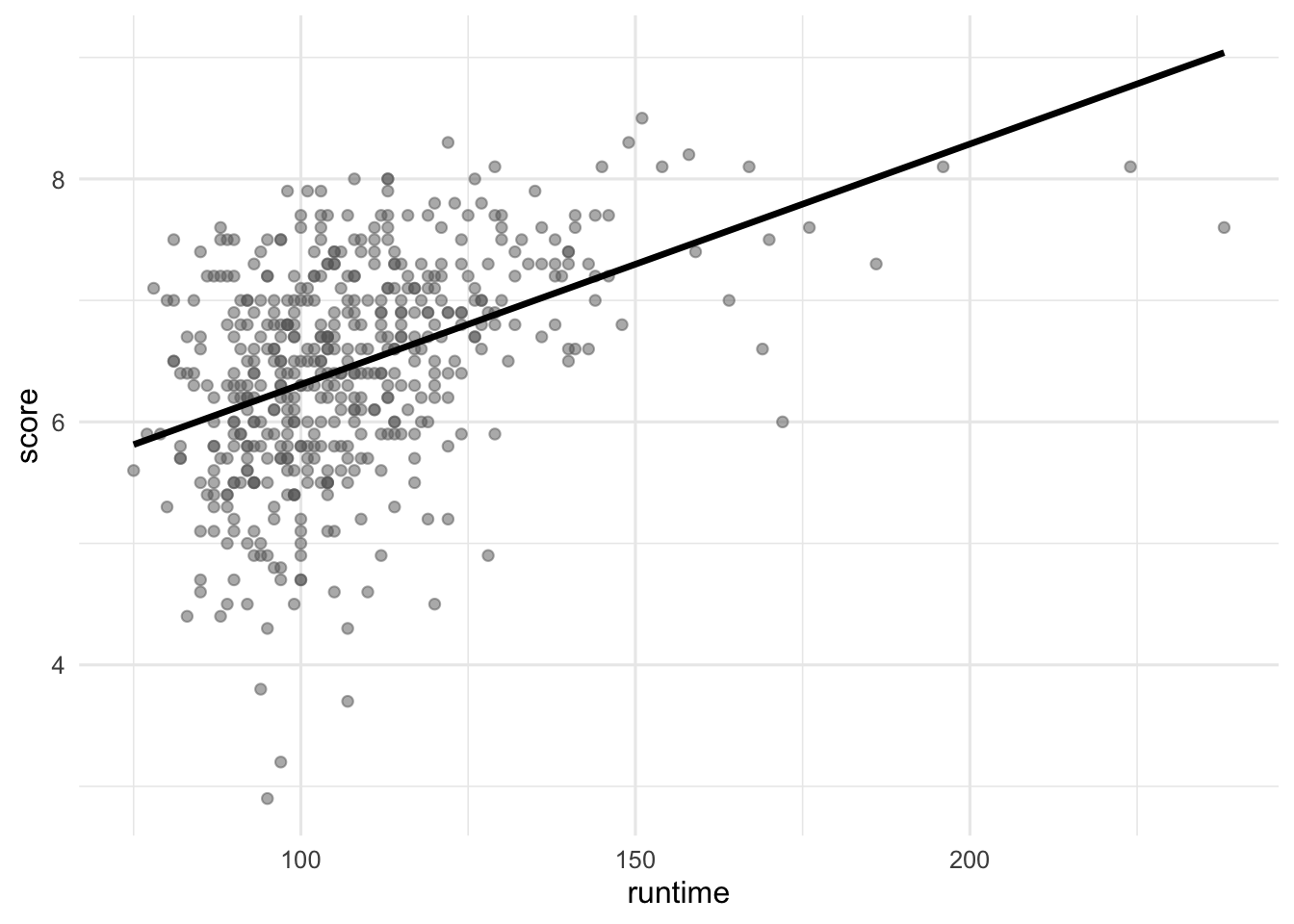
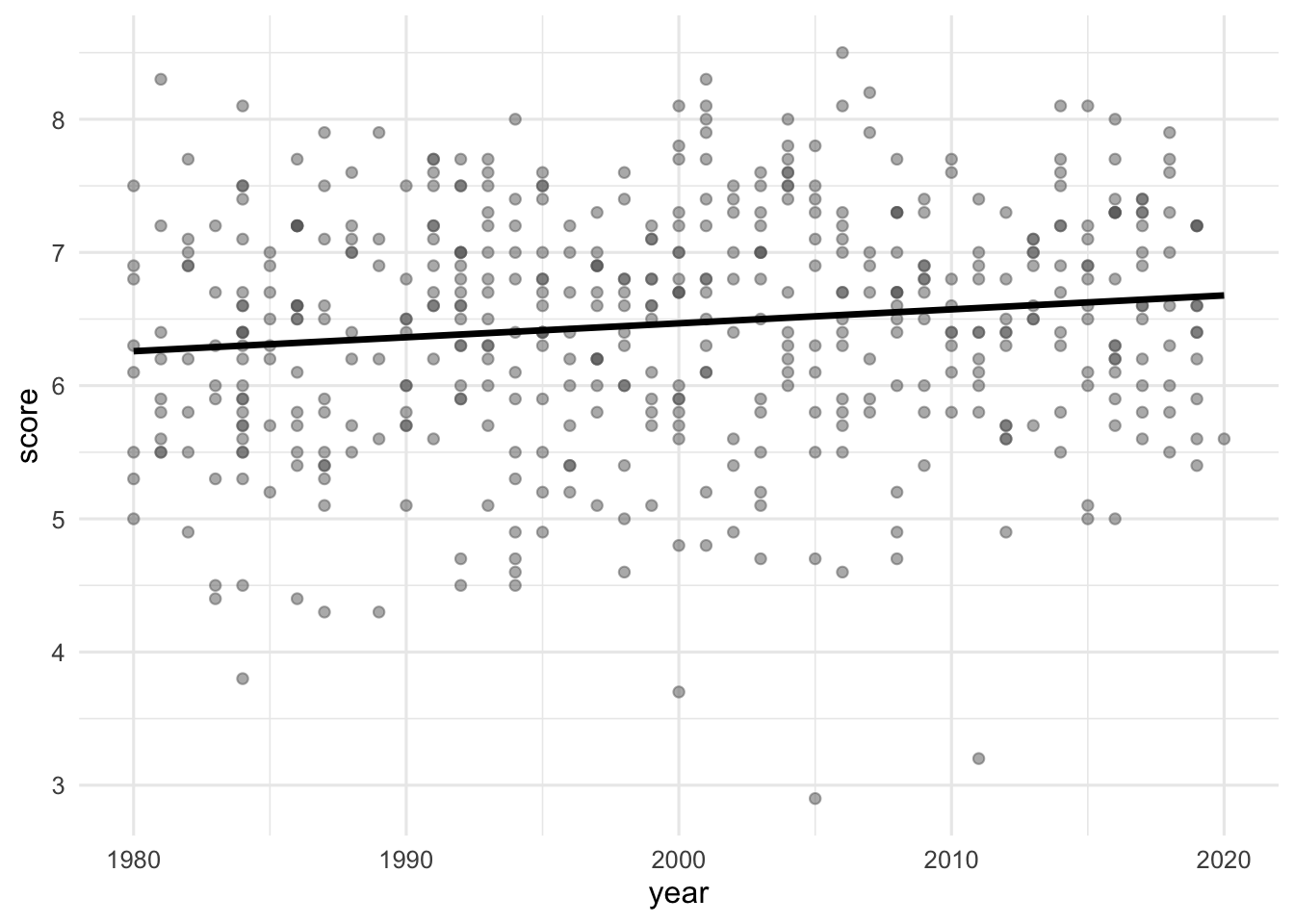
The correlation coefficients of these relationships are calculated below, though some of the code and the output are missing. Answer all questions in this part based on the code and output shown below.
movies |>
__blank_1__(
r_score_runtime = cor(runtime, score),
r_score_year = cor(year, score)
)# A tibble: 1 × 2
r_score_runtime r_score_year
<dbl> <dbl>
1 0.434. __blank_2__ Question 30
Which of the following goes in __blank_1__?
summarizemutategroup_byarrangefilter
Question 31
What can we say about the value that goes in __blank_2__?
NAA value between 0 and 0.434.
A value between 0.434 and 1.
A value between 0 and -0.434.
A value between -1 and -0.434.
Score vs. runtime and rating
In this part, we fit a model predicting score from runtime and rating (categorized as G, PG, PG-13, R, NC-17, and Not Rated), and name it score_runtime_rating_fit.
The model output for score_runtime_rating_fit is shown in Table 3. Answer all questions in this part based on Table 3.
score_runtime_rating_fit.
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 4.525 | 0.332 | 13.647 | 0.000 |
| runtime | 0.021 | 0.002 | 10.702 | 0.000 |
| ratingPG | -0.189 | 0.295 | -0.642 | 0.521 |
| ratingPG-13 | -0.452 | 0.292 | -1.547 | 0.123 |
| ratingR | -0.257 | 0.285 | -0.901 | 0.368 |
| ratingNC-17 | -0.355 | 0.486 | -0.730 | 0.466 |
| ratingNot Rated | -0.282 | 0.328 | -0.860 | 0.390 |
Question 32
Which of the following is TRUE about the intercept of score_runtime_rating_fit? Select all that are true.
Keeping runtime constant, G-rated movies are predicted to score, on average, 4.525 points.
Keeping runtime constant, movies without a rating are predicted to score, on average, 4.525 points.
Movies without a rating that are 0 minutes in length are predicted to score, on average, 4.525 points.
All else held constant, movies that are 0 minutes in length are predicted to score, on average, 4.525 points.
G-rated movies that are 0 minutes in length are predicted to score, on average, 4.525 points.
Question 33
Which of the following is the best interpretation of the slope of runtime in score_runtime_rating_fit?
All else held constant, as runtime increases by 1 minute, the score of the movie increases by 0.021 points.
For G-rated movies, all else held constant, as runtime increases by 1 minute, we predict the score of the movie to be higher by 0.021 points on average.
All else held constant, for each additional minute of runtime, movie scores will be higher by 0.021 points on average.
G-rated movies that are 0 minutes in length are predicted to score 0.021 points on average.
For each higher level of rating, the movie scores go up by 0.021 points on average.
Question 34
Fill in the blank:
R-squared for
score_runtime_rating_fit(the model predictingscorefromruntimeandrating) _________ the R-squared the modelscore_runtime_fit(for predictingscorefromruntimealone).
is less than
is equal to
is greater than
cannot be compared (based on the information provided) to
is both greater than and less than
Question 35
The model score_runtime_rating_fit (the model predicting score from runtime and rating) can be visualized as parallel lines for each level of rating. Which of the following is the equation of the line for R-rated movies?
\(\widehat{score} = (4.525 - 0.257) + 0.021 \times runtime\)
\(score = (4.525 - 0.257) + 0.021 \times runtime\)
\(\widehat{score} = 4.525 + (0.021 - 0.257) \times runtime\)
\(score = 4.525 + (0.021 - 0.257) \times runtime\)
\(\widehat{score} = (4.525 + 0.021) - 0.257 \times runtime\)